基于 CRAQ 的对象存储
面向读密集型工作负载的高吞吐量链式复制
摘要
大规模存储系统通常将数据在众多可能存在故障的组件上进行复制和分区,以提供可靠性和可扩展性。然而,许多商业部署的系统,特别是那些设计用于客户交互式使用的系统,为了追求更高的可用性和更高的吞吐量,牺牲了更强的一致性属性。
本文描述了 CRAQ(Chain Replication with Apportioned Queries,按比例分配查询的链式复制)的设计、实现和评估,这是一个分布式对象存储系统,挑战了这种僵化的权衡取舍。我们的基本方法是对链式复制(Chain Replication)的改进,在保持强一致性的同时,极大地提高了读取吞吐量。通过将负载分布到所有对象副本上,CRAQ 能够随着链的大小线性扩展,而无需增加一致性协调开销。同时,当某些应用满足于较弱的一致性保证时,它暴露未提交的操作,这在系统高变动(churn)时期尤其有用。本文探讨了在多个数据中心进行地理复制的 CRAQ 存储的额外设计和实现考量,以提供位置优化的操作。我们还讨论了用于多对象原子更新的多对象原子更新(multi-object atomic updates)以及用于大对象更新的多播优化(multicast optimizations)。
1 引言
许多在线服务需要基于对象(object-based)的存储,其中数据以完整单元的形式呈现给应用程序。对象存储支持两个基本原语:读取(或查询,read)操作返回存储在对象名称下的数据块,写入(或更新,write)操作更改单个对象的状态。这种基于对象的存储由键值数据库(例如 BerkeleyDB [^40] 或 Apache 的半结构化 CouchDB [^13])到部署在商业数据中心的大规模可扩展系统(例如 Amazon 的 Dynamo [^15]、Facebook 的 Cassandra [^16] 和流行的 Memcached [^18])所支持。为了在许多此类系统中实现所需的可靠性、负载平衡和可扩展性,对象命名空间在众多机器上进行分区,并且每个数据对象被复制多次。
当应用程序有特定要求时,基于对象的系统比其文件系统对应物更具吸引力。对象存储更适用于平面命名空间(例如键值数据库),而不是分层目录结构。对象存储简化了对整个对象修改的支持过程。并且,它们通常只需要推理对特定对象的修改顺序,而不是整个存储系统;为每个对象提供一致性保证比跨所有操作和/或对象提供要便宜得多。
在为其众多应用构建底层存储系统时,商业站点将高性能和高可用性的需求放在首位。数据被复制以承受单个节点甚至整个数据中心的故障,无论是计划内维护还是计划外故障。事实上,新闻媒体充斥着数据中心离线导致整个网站宕机的例子 [^26]。这种对可用性和性能的强烈关注——特别是当这些属性被编入严格的 SLA(服务级别协议)要求时 [^4] [^24]——导致许多商业系统牺牲了强一致性(strong consistency)语义,因为它们被认为成本过高(例如在 Google [^22]、Amazon [^15]、eBay [^46] 和 Facebook [^44] 等公司中)。
最近,van Renesse 和 Schneider 提出了一种用于故障停止(fail-stop)服务器上对象存储的链式复制(chain replication)方法 [^47],旨在提供强一致性同时提高吞吐量。基本方法将所有存储对象的节点组织成一条链(chain),链的尾节点(tail)处理所有读请求,链的头节点(head)处理所有写请求。写操作在客户端收到确认(acknowledged)之前沿着链向下传播,从而在尾节点处为所有对象操作提供了一个简单的总排序——因此提供了强一致性。缺乏任何复杂或多轮协议带来了简单性、良好的吞吐量和易于恢复。
不幸的是,基本的链式复制方法有一些局限性。对一个对象的所有读取都必须发送到同一个节点,这可能导致热点(hotspots)。可以通过一致哈希(consistent hashing)[^29] 或更中心化的目录方法 [^22] 在集群节点上构建多条链以实现更好的负载平衡——但这些算法可能仍然会发现负载不平衡,如果特定对象异常受欢迎,这在实践中是一个真实的问题 [^17]。当尝试跨多个数据中心构建链时,可能出现一个更严重的问题,因为对一条链的所有读取可能都需要由一个可能很远的节点(链的尾节点)处理。
本文介绍了 CRAQ(Chain Replication with Apportioned Queries)的设计、实现和评估,这是一个对象存储系统,在保持链式复制 [^47] 的强一致性属性的同时,通过支持按比例分配查询(apportioned queries)来为读取操作提供更低的延迟和更高的吞吐量:也就是说,将读取操作分配到链中的所有节点,而不是要求它们都由单个主节点处理。本文的主要贡献如下:
- CRAQ 允许任何链节点处理读取操作,同时保持强一致性,从而支持在存储对象的所有节点之间进行负载平衡。此外,当工作负载主要是读取时——这是其他系统(如 Google 文件系统 [^22] 和 Memcached [^18])使用的假设——CRAQ 的性能可与仅提供最终一致性(eventual consistency)的系统相媲美。
- 除了强一致性,CRAQ 的设计自然地支持读取操作之间的最终一致性,以在写入争用期间实现更低延迟的读取,并在瞬时分区期间降级为只读行为。CRAQ 允许应用程序为读取操作指定可接受的最大陈旧度(staleness)。
- 利用这些负载平衡特性,我们描述了一个广域系统设计,用于在跨地理上分散的集群上构建 CRAQ 链,同时保留强局部性(locality)属性。具体来说,读取操作可以完全由本地集群处理,或者在最坏的情况下,在高写入争用期间只需要在广域网上传输简洁的元数据信息。我们还介绍了我们如何使用 ZooKeeper [^48](一个类似 PAXOS 的组成员服务系统)来管理这些部署。
最后,我们讨论了 CRAQ 的额外扩展,包括集成用于多对象原子更新的迷你事务(mini-transactions),以及使用多播(multicast)来提高大对象更新的写入性能。然而,我们尚未完成这些优化的实现。
CRAQ 的初步性能评估表明,与基本的链式复制方法相比,它具有更高的吞吐量,对于读密集型工作负载,吞吐量随链节点数量线性扩展:对于三节点链大约提高了 200%,对于七节点链提高了 600%。在高写入争用期间,CRAQ 在三节点链上的读取吞吐量仍然是链式复制的两倍,并且读取延迟保持较低水平。我们描述了它在不同工作负载和故障下的性能特征。最后,我们评估了 CRAQ 在地理复制存储方面的性能,证明了其延迟显著低于基本链式复制所能达到的水平。
本文的其余部分组织如下。第 2 节比较了基本链式复制和 CRAQ 协议,以及 CRAQ 对最终一致性的支持。第 3 节描述了在数据中心内部和跨数据中心扩展 CRAQ 到多条链,以及管理链和节点的组成员服务。第 4 节涉及扩展,如多对象更新和利用多播。第 5 节描述了我们的 CRAQ 实现,第 6 节展示了我们的性能评估,第 7 节回顾了相关工作,第 8 节是结论。
2 基本系统模型
本节介绍我们基于对象的接口和一致性模型,简要概述标准的链式复制模型,然后介绍强一致性的 CRAQ 及其较弱变体。
2.1 接口和一致性模型
基于对象的存储系统为用户提供两个简单的原语:
write(objID, V):写入(更新)操作存储与对象标识符objID关联的值 (V)。V ← read(objID):读取(查询)操作检索与对象 IDobjID关联的值 (V)。
我们将讨论针对单个对象的两种主要一致性类型:
- 强一致性(Strong Consistency):在我们的系统中提供这样的保证:对一个对象的所有读写操作都以某种顺序执行,并且对对象的读取总是能看到最新写入的值。
- 最终一致性(Eventual Consistency):在我们的系统中意味着对对象的写入仍然在所有节点上按顺序应用,但最终一致性的读取操作在不同节点上可能会在一段不一致时期内(i.e.,在写入应用到所有节点之前)返回陈旧数据。然而,一旦所有副本接收到写入,读取操作将永远不会返回比这个最新已提交写入更旧的版本。事实上,如果客户端与特定节点维持一个会话(session),它也会看到单调读一致性(monotonic read consistency)¹(尽管在不同节点的会话之间则不会)。
我们接下来考虑链式复制和 CRAQ 如何提供它们的强一致性保证。
2.2 链式复制(Chain Replication)
链式复制(CR)是一种在多个节点间复制数据的方法,提供强一致的存储接口。节点形成一条定义长度为 (C) 的链(chain)。链的头节点(head)处理来自客户端的所有写入(write)操作。当一个节点接收到写操作时,它会传播给链中的下一个节点。一旦写入到达尾节点(tail),它就已经应用到链中的所有副本,此时它被认为是已提交的(committed)。尾节点处理所有读取(read)操作,因此只有已提交的值才能通过读取返回。
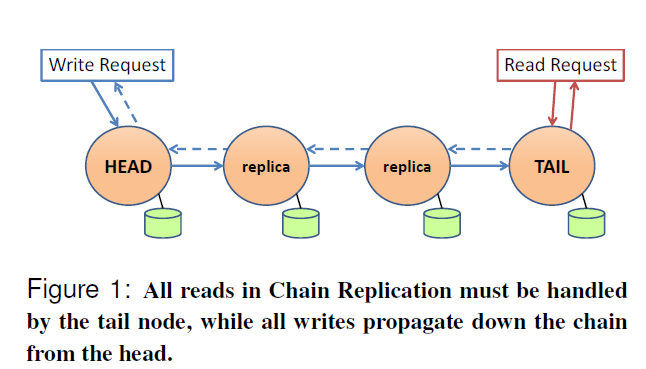
图 1:链式复制中的所有读取必须由尾节点处理,而所有写入则从头部沿链向下传播。
图 1 展示了一个长度为四的链示例。所有读请求到达尾节点并被其处理。写请求到达链的头部,并沿着链向下传播到尾节点。当尾节点提交写入时,会向客户端发送回复。CR 论文描述的是尾节点直接向客户端发送消息;因为我们使用 TCP,我们的实现实际上是在头节点收到尾节点的确认(acknowledgment)后(利用其与客户端预先存在的网络连接)进行响应。这种确认传播在图中用虚线表示。
CR 的简单拓扑结构使得写操作比提供强一致性的其他协议更便宜。多个并发写入可以在链上流水线化(pipelined),传输成本平均分摊到所有节点。先前工作 [^47] 的仿真结果表明,与主/备(primary/backup)复制相比,CR 具有竞争力或更优的吞吐量,同时论证了其更快、更易恢复的主要优势。
链式复制实现了强一致性:由于所有读取都发送到尾节点,并且所有写入只有在到达尾节点时才被提交,链尾节点可以轻松地为所有操作应用一个总排序。然而,这是有代价的,因为它将读取吞吐量降低到单个节点的水平,而无法随链的大小扩展。但这是必要的,因为查询中间节点可能会违反强一致性保证;具体来说,对不同节点的并发读取可能会在写入沿链传播的过程中看到不同的写入。
虽然 CR 专注于提供存储服务,但人们也可以将其查询/更新协议视为复制状态机(replicated state machine)的接口(尽管它们影响的是不同的对象)。人们可以类似地看待 CRAQ,尽管本文的其余部分仅从读/写(也称为 get/put 或 query/update)对象存储接口的角度来考虑问题。
2.3 按比例分配查询的链式复制(Chain Replication with Apportioned Queries - CRAQ)
受读密集型工作负载环境普及的推动,CRAQ 旨在通过允许链中的任何节点处理读取操作来提高读取吞吐量,同时仍提供强一致性保证。CRAQ 的主要扩展如下:
- CRAQ 中的节点可以存储对象的多个版本(version),每个版本包括一个单调递增的版本号(version number)和一个额外属性,指示该版本是干净的(clean)还是脏的(dirty)。所有版本最初都标记为干净的。
- 当节点接收到对象的新版本时(通过沿链向下传播的写入),该节点将此最新版本追加到该对象的列表中。
- 如果该节点不是尾节点,它将版本标记为脏的,并将写入传播给其后继节点(successor)。
- 否则,如果该节点是尾节点,它将版本标记为干净的,此时我们称该对象版本(写入)为已提交的(committed)。尾节点然后可以通过沿链向后发送确认(acknowledgment)来通知所有其他节点该提交。
- 当对象版本的确认(acknowledgment)消息到达一个节点时,该节点将该对象版本标记为干净的。然后该节点可以删除该对象的所有先前版本。
- 当节点接收到对对象的读取请求时:
- 如果所请求对象的最新已知版本是干净的,节点返回此值。
- 否则,如果所请求对象的最新版本号是脏的,节点联系尾节点并询问尾节点的最后提交版本号(一个版本查询,version query)。然后节点返回该版本的对象;根据设计,保证该节点存储着这个对象版本。我们注意到,尽管尾节点可能在回复版本请求之后、中间节点向客户端发送回复之前提交一个新版本,但这并不违反我们对强一致性的定义,因为读取操作是相对于尾节点串行化的(read operations are serialized with respect to the tail)。
请注意,节点上对象的“脏”或“干净”状态也可以隐式确定,前提是节点在收到写入提交确认后立即删除旧版本。即,如果节点对某个对象恰好只有一个版本,则该对象隐式处于干净状态;否则,该对象是脏的,必须从链尾检索正确顺序的版本。
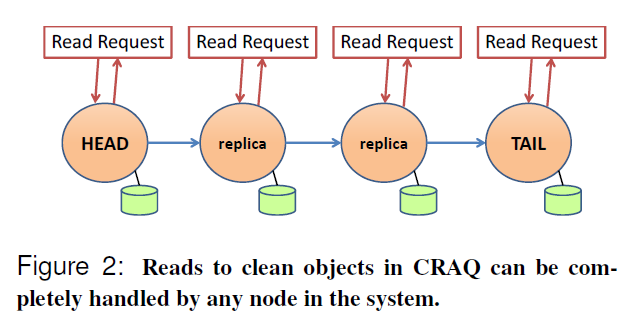
图 2:在 CRAQ 中,对干净对象的读取可以完全由系统中的任何节点处理。
图 2 显示了一个处于起始干净状态的 CRAQ 链。每个节点存储对象的相同副本,因此任何到达链中任何节点的读请求都将返回相同的值。除非接收到写操作,否则所有节点都保持干净状态。²
脚注 2:关于干净读取的系统排序属性有一个小注意事项。在传统的链式复制中,所有操作都由尾节点处理,因此它显式地定义了影响一个对象的所有操作的总排序。在 CRAQ 中,对不同节点的干净读取操作是本地执行的;因此,虽然可以为这些“并发”读取定义一个(任意的)总排序,但系统并不显式地这样做。当然,两个系统都显式地(在尾节点)维护了所有读/写、写/读和写/写关系的总排序。
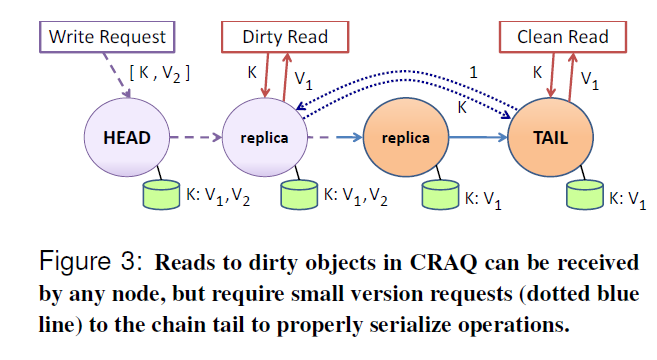
图 3:在 CRAQ 中,对脏对象的读取可以由任何节点接收,但需要向链尾发送小的版本请求(蓝色点线)以正确串行化操作。
在图 3 中,我们展示了一个传播过程中的写操作(用紫色虚线表示)。头节点接收到写入对象新版本 ((V~2~)) 的初始消息,因此头节点的对象是脏的。然后它将写消息传播给链中的第二个节点,该节点也将其对象标记为脏的(为单个对象 ID (K) 存储了多个版本 [V~1~,V~2~])。如果读取请求由干净的节点之一接收,它们立即返回对象的旧版本:这是正确的,因为新版本尚未在尾节点提交。然而,如果读取请求由任何一个脏节点接收,它们会向尾节点发送一个版本查询——图中用蓝色点线箭头表示——尾节点返回其已知的请求对象版本 (1)。然后脏节点返回与此指定版本号关联的旧对象值 (V~1~)。因此,链中的所有节点仍将返回对象的相同版本,即使有多个未完成的写入正在沿链传播。
当尾节点接收并接受写请求时,它会发送一条包含此写入版本号的确认消息沿链返回。当每个前驱节点(predecessor)接收到确认时,它将指定版本标记为干净的(可能删除所有旧版本)。当它最新知道的版本变为干净时,它随后可以本地处理读取。此方法利用了写入都是串行传播的事实,因此尾节点总是最后接收写入的链节点。
CRAQ 相对于 CR 的吞吐量提升出现在两种不同的场景中:
- 读密集型工作负载(Read-Mostly Workloads):大部分读请求仅由 (C-1) 个非尾节点处理(作为干净读取),因此在这些场景下,吞吐量随链大小 (C) 线性扩展。
- 写密集型工作负载(Write-Heavy Workloads):大部分对非尾节点的读请求是脏的,因此需要向尾节点发送版本查询。然而,我们建议这些版本查询比完整读取更轻量级,允许尾节点在被饱和之前以更高的速率处理它们。这导致总的读取吞吐量仍然高于 CR。
第 6 节的性能结果支持了这两个主张,即使对于小对象也是如此。对于持续写密集型的较长链,人们可以想象通过让尾节点仅处理版本查询而不处理完整读请求来优化读取吞吐量,尽管我们尚未评估此优化。
2.4 CRAQ 上的一致性模型(Consistency Models on CRAQ)
一些应用程序可能能够在较弱一致性保证下运行,它们可能希望避免版本查询的性能开销(在广域网部署中可能很显著,见第 3.3 节),或者希望在系统无法提供强一致性时(例如,在分区期间)继续运行。为了支持这种需求的变化,CRAQ 同时支持三种不同的读取一致性模型。读取操作通过注解指定允许使用哪种一致性类型。
- 强一致性(Strong Consistency)(默认)如上述模型(第 2.1 节)所述。所有对象读取都保证与最后提交的写入一致。
- 最终一致性(Eventual Consistency) 允许对链节点的读取操作返回它已知的最新对象版本。因此,随后对另一个不同节点的读取操作可能返回比先前返回版本更旧的对象版本。因此,这不满足单调读一致性(monotonic read consistency),尽管对单个链节点的读取在本地(即作为会话的一部分)确实保持此属性。
- 具有最大不一致界限的最终一致性(Eventual Consistency with Maximum-Bounded Inconsistency) 允许读取操作在对象提交之前返回新写入的对象,但仅限于某个限度。施加的限制可以基于时间(相对于节点的本地时钟)或绝对版本号。在此模型中,从读取操作返回的值保证具有最大不一致期(定义在时间或版本控制上)。如果链仍然可用,这种不一致性实际上是返回的版本比最后提交的版本更新。如果系统被分区且节点无法参与写入,该版本可能比当前提交的版本更旧。
2.5 CRAQ 中的故障恢复(Failure Recovery in CRAQ)
由于 CRAQ 的基本结构与 CR 相似,CRAQ 使用相同的技术从故障中恢复。非正式地说,每个链节点需要知道它的前驱(predecessor)和后继(successor),以及链的头和尾。当头节点故障时,它的直接后继接管成为新的链头;同样,尾节点故障时,它的前驱接管。节点加入链中间或从链中间故障时,必须将自己插入到两个节点之间,很像一个双向链表。处理系统故障的正确性证明与 CR 类似;由于篇幅限制,我们在此省略。第 5 节描述了 CRAQ 中故障恢复的细节,以及我们协调服务的集成。特别是,CRAQ 允许节点加入链中任意位置(而不是仅在尾部 [^47])的选择,以及在恢复期间正确处理故障,需要一些仔细的考量。
3 扩展 CRAQ(Scaling CRAQ)
在本节中,我们讨论应用程序如何在 CRAQ 中指定各种链布局方案,无论是在单个数据中心内部还是跨多个数据中心。然后我们描述如何使用协调服务来存储链元数据和组成员信息。
3.1 链放置策略(Chain Placement Strategies)
使用分布式存储服务的应用程序在其需求上可能多种多样。可能发生的一些常见情况包括:
- 对某个对象的大多数或所有写入可能源自单个数据中心。
- 某些对象可能仅与数据中心的子集相关。
- 热门对象可能需要大量复制,而不受欢迎的对象则可以很少。
CRAQ 通过使用对象的两级命名层次结构(hierarchy)来提供灵活的链配置策略以满足这些不同的需求。对象的标识符由链标识符(chain identifier)和键标识符(key identifier)组成。链标识符决定 CRAQ 中哪些节点将存储该链内的所有键,而键标识符提供每个链内的唯一命名。我们描述了多种指定应用需求的方式:
隐式数据中心和全局链大小(Implicit Datacenters & Global Chain Size):
{num_datacenters, chain_size}在此方法中,定义了将存储链的数据中心数量,但没有明确指定是哪些数据中心。为了精确确定哪些数据中心存储链,使用一致哈希(consistent hashing)和唯一的数据中心标识符。显式数据中心和全局链大小(Explicit Datacenters & Global Chain Size):
{chain_size, dc₁, dc₂, …, dc_N}使用此方法,每个数据中心使用相同的链大小在其内部存储副本。链的头节点位于数据中心 (dc₁) 内,链的尾节点位于数据中心 (dcN) 内,链的顺序基于提供的数据中心列表确定。为了确定数据中心内哪些节点存储分配给链的对象,对链标识符使用一致哈希。每个数据中心 (dc~i~) 有一个节点分别连接到数据中心 (dc~i-1~) 的尾节点和连接到数据中心 (dc~i+1~) 的头节点。一个额外的增强是允许 (chain_size) 为 0,这表示链应使用每个数据中心内的所有节点。显式数据中心链大小(Explicit Datacenter Chain Sizes):
{dc₁, chain_size₁, …, dc_N, chain_size_N}这里分别指定了每个数据中心内的链大小。这允许链负载平衡的非均匀性。每个数据中心内的链节点选择方式与之前的方法相同,并且 (chain_size~i~) 也可以设置为 0。
在上述方法 2 和 3 中,(dc₁) 可以设置为主数据中心(master datacenter)。如果一个数据中心是链的主节点,这意味着在瞬时故障期间,只有该数据中心会接受对该链的写入。否则,如果 (dc₁) 与链的其余部分断开连接,(dc₂) 可以成为新的头节点并接管写操作,直到 (dc₁) 重新上线。当未定义主节点时,只有在分区包含全局链中大多数节点时,该分区才会继续写入。否则,该分区将变为只读,以支持第 2.4 节定义的最大不一致界限读取操作。
CRAQ 可以轻松支持其他更复杂的链配置方法。例如,可能需要指定一个显式的备份数据中心,该数据中心仅在另一个数据中心故障时才参与链。也可以定义一组数据中心(例如,“东海岸”),其中任何一个可以填充方法 2 的有序数据中心列表中的单个位置。为简洁起见,我们不详述更复杂的方法。
写入单个链的键标识符数量没有限制。这允许根据应用程序需求高度灵活地配置链。
3.2 数据中心内的 CRAQ(CRAQ within a Datacenter)
如何在数据中心内分布多条链的选择在原始的链式复制工作中已研究过。在 CRAQ 的当前实现中,我们使用一致哈希(consistent hashing)[29, 45] 将链放置在数据中心内,将可能多个链标识符映射到单个头节点。这与越来越多的基于数据中心的对象存储 [15, 16] 类似。GFS [^22] 采用并在 CR [^47] 中推广的另一种方法是,使用成员管理服务作为目录服务来分配和存储随机的链成员关系,即每条链可以包含一组随机的服务器节点。这种方法提高了并行系统恢复的潜力。然而,它的代价是增加了中心化和状态。CRAQ 也可以轻松使用这种替代的组织设计,但这需要在协调服务中存储更多的元数据信息。
3.3 跨多个数据中心的 CRAQ(CRAQ Across Multiple Datacenters)
当链跨越广域网时,CRAQ 从任何节点读取的能力改善了其延迟:当客户端在选择节点方面有灵活性时,它们可以选择一个附近的(甚至负载较轻的)节点。只要链是干净的,该节点就可以返回其本地对象副本,而无需发送任何广域网请求。另一方面,使用传统的 CR,所有读取都需要由可能很远的尾节点处理。事实上,各种设计可能会根据其数据中心来选择链中的头和/或尾节点,因为对象可能表现出显著的引用局部性(reference locality)。确实,Yahoo! 的新分布式数据库 PNUTS [^12] 的设计就是受到其数据中心中观察到的高写入局部性的启发。
也就是说,应用程序可以进一步优化广域网链的选择,以最小化写入延迟并降低网络成本。当然,在整个全局节点集上使用一致哈希构建链的朴素方法会导致随机的链后继和前驱节点,可能相距甚远。此外,单个链可能多次进出数据中心(或数据中心内的特定集群)。另一方面,利用我们的链优化,应用程序可以通过仔细选择构成链的数据中心顺序来最小化写入延迟,并且我们可以确保单条链在每个方向只穿越一次数据中心的网络边界。
即使使用优化的链,随着更多数据中心加入链,通过广域网链路的写操作延迟也会增加。尽管与并行分发写入的主/备方法相比,这种增加的延迟可能很显著,但它允许写入在链上流水线化(pipelined)。这大大提高了相对于主/备方法的写入吞吐量。
3.4 ZooKeeper 协调服务(ZooKeeper Coordination Service)
为分布式应用程序构建容错的协调服务是众所周知的容易出错。CRAQ 的早期版本包含一个非常简单的、中心控制的协调服务来维护成员管理。然而,我们随后选择利用 ZooKeeper [^48] 为 CRAQ 提供一种健壮的、分布式的、高性能的跟踪组成员的方法,以及一种存储链元数据的简便方式。通过使用 ZooKeeper,保证 CRAQ 节点在节点添加到组或从组中移除时收到通知。类似地,当节点对其感兴趣(expressed interest)的元数据发生变化时,该节点可以被通知。
ZooKeeper 向客户端提供类似文件系统的分层命名空间(hierarchical namespace)。文件系统存储在内存中,并在每个 ZooKeeper 实例上备份到日志中,文件系统状态在多个 ZooKeeper 节点之间复制,以实现可靠性和可扩展性。为了达成一致,ZooKeeper 节点使用一种原子广播(atomic broadcast)协议,类似于两阶段提交(two-phase-commit)。ZooKeeper 针对读密集型、小型工作负载进行了优化,在面对大量读取者时提供良好的性能,因为它可以从内存中为大多数请求提供服务。
类似于传统的文件系统命名空间,ZooKeeper 客户端可以列出目录内容、读取与文件关联的值、向文件写入值,以及在文件或目录被修改或删除时接收通知。ZooKeeper 的原语操作允许客户端实现许多更高级的语义,如组成员关系、领导者选举(leader election)、事件通知、锁(locking)和队列(queuing)。
跨多个数据中心的成员管理和链元数据确实带来了一些挑战。事实上,ZooKeeper 并未针对在多数据中心环境中运行进行优化:在单个数据中心内放置多个 ZooKeeper 节点提高了该数据中心内 ZooKeeper 读取的可扩展性,但代价是广域网性能。由于原始实现不了解数据中心拓扑或层次结构的概念,ZooKeeper 节点之间的协调消息会多次在广域网上传输。尽管如此,我们当前的实现确保 CRAQ 节点总是从本地 ZooKeeper 节点接收通知,并且它们只会收到与其相关的链和节点列表的进一步通知。我们在第 5.1 节详细介绍了通过 ZooKeeper 进行的协调。
为了消除跨数据中心 ZooKeeper 流量的冗余,可以构建一个 ZooKeeper 实例的层次结构:每个数据中心可以包含其自己的本地 ZooKeeper 实例(由多个节点组成),并有一个代表参与全局 ZooKeeper 实例(可能通过本地实例中的领导者选举选出)。然后单独的功能可以协调两者之间的数据共享。另一种设计是修改 ZooKeeper 本身,使节点感知网络拓扑,就像 CRAQ 目前所做的那样。我们尚未充分研究这两种方法,将其留作未来工作。
4 扩展(Extensions)
本节讨论 CRAQ 的一些额外扩展,包括其支持迷你事务(mini-transactions)的能力以及使用多播(multicast)来优化写入。我们目前正在实施这些扩展。
4.1 CRAQ 上的迷你事务(Mini-Transactions on CRAQ)
对象存储的整对象读/写接口可能对某些应用程序有限制。例如,BitTorrent tracker 或其他目录服务可能希望支持列表添加或删除。分析服务可能希望存储计数器。或者应用程序可能希望提供对某些对象的条件访问。仅凭目前描述的纯对象存储接口,这些都不容易提供,但 CRAQ 提供了支持事务操作的关键扩展。
4.1.1 单键操作(Single-Key Operations)
几种单键操作很容易实现,CRAQ 已经支持:
- 前置/追加(Prepend/Append):将数据添加到对象当前值的开头或结尾。
- 递增/递减(Increment/Decrement):对键的对象(解释为整数值)进行加减操作。
- 测试并设置(Test-and-Set):仅当键对象的当前版本号等于操作中指定的版本号时才更新该键的对象。
对于前置/追加和递增/递减操作,存储键对象的链头节点可以简单地将操作应用于对象的最新版本(即使最新版本是脏的),然后沿链向下传播一个完整的替换写入。此外,如果这些操作频繁,头节点可以缓冲请求并批量更新。使用传统的两阶段提交协议,这些增强将昂贵得多。
对于测试并设置操作,链头检查其最近提交的版本号是否等于操作中指定的版本号。如果对象没有未完成的未提交版本,头节点接受操作并沿链向下传播更新。如果有未完成的写入,我们直接拒绝测试并设置操作,客户端在被连续拒绝时会小心地降低其请求速率。或者,头节点可以通过禁止写入来“锁定”对象,直到对象变干净,然后重新检查最新的提交版本号,但由于未提交的写入被中止的情况非常罕见,并且锁定对象会显著影响性能,我们选择不实现此替代方案。
测试并设置操作也可以设计为接受一个值而不是版本号,但这在有未完成的未提交版本时会引入额外的复杂性。如果头节点与对象最近提交的版本(通过联系尾节点)进行比较,任何当前正在进行的写入都不会被考虑。如果头节点与最近的未提交版本进行比较,这违反了一致性保证。为了实现一致性,头节点需要通过禁止(或暂时延迟)写入来临时锁定对象,直到对象变干净。这不违反一致性保证并确保没有更新丢失,但可能会显著影响写入性能。
4.1.2 单链操作(Single-Chain Operations)
Sinfonia 最近提出的“迷你事务(mini-transactions)”提供了一种有吸引力的轻量级方法 [^2],用于在单链内的多个键上执行事务。一个迷你事务由一个比较集(compare set)、读集(read set)和写集(write set)定义;Sinfonia 在许多存储节点上暴露一个线性地址空间。比较集测试指定地址位置的值,如果它们与提供的值匹配,则执行读和写操作。通常为低写入争用环境设计,Sinfonia 的迷你事务使用乐观的两阶段提交协议。准备(prepare)消息尝试获取每个指定内存地址的锁(或者因为指定了不同的地址,或者为了容错在多个节点上实现相同的地址空间)。如果所有地址都能被锁定,协议提交;否则,参与者释放所有锁并稍后重试。
CRAQ 的链拓扑结构在支持类似的迷你事务方面有一些特殊优势,因为应用程序可以指定多个对象存储在同一条链上——即那些在多对象迷你事务中经常一起出现的对象——以保留局部性的方式。共享相同 chainid 的对象将被分配到同一个节点作为其链头,从而将两阶段提交减少为单次交互,因为只涉及一个头节点。CRAQ 的独特之处在于,仅涉及单条链的迷你事务可以仅使用单个头节点来协调访问,因为它控制着链上所有键的写入访问,而不是所有链节点。唯一的权衡是,如果头节点需要等待事务中的键变为干净(如第 4.1.1 节所述),写入吞吐量可能会受到影响。也就是说,这个问题在 Sinfonia 中更严重,因为它需要等待(通过指数回退迷你事务请求)跨多个节点的未锁定键。故障恢复在 CRAQ 中也同样更容易。
4.1.3 多链操作(Multi-Chain Operations)
即使在多对象更新涉及多条链时,乐观的两阶段协议也只需要在链头之间实现,而不是所有涉及的节点。链头可以锁定迷你事务中涉及的任何键,直到它完全提交。
当然,应用程序开发人员应谨慎使用大量锁定和迷你事务:它们降低了 CRAQ 的写入吞吐量,因为对同一对象的写入不能再流水线化,而流水线化正是链式复制的一大优势。
4.2 使用多播降低写入延迟(Lowering Write Latency with Multicast)
CRAQ 可以利用多播协议(multicast protocols)[^41] 来提高写入性能,特别是对于大更新或长链。由于链成员在节点成员关系变化之间是稳定的,因此可以为每条链创建一个多播组(multicast group)。在数据中心内部,这可能采用网络层多播协议的形式,而应用层多播协议可能更适合广域网链。这些多播协议不需要提供顺序或可靠性保证。
然后,不是将完整的写入串行地沿链传播(这会增加与链长度成比例的延迟),实际值可以通过多播发送给整个链。然后,只需要沿链传播一个小的元数据消息,以确保在尾节点之前所有副本都已接收到写入。如果节点因任何原因未收到多播,它可以在收到写提交消息之后、进一步传播提交消息之前,从其前驱节点获取对象。
此外,当尾节点接收到传播的写请求时,可以向多播组发送一个多播确认消息,而不是沿链向后传播它。这既减少了节点对象在写入后重新进入干净状态所需的时间,也减少了客户端感知的写入延迟。同样,多播确认时不需要顺序或可靠性保证——如果链中的节点没有收到确认,它将在下一次读取操作需要查询尾节点时重新进入干净状态。
5 管理与实现(Management and Implementation)
我们的链式复制和 CRAQ 原型实现使用 C++ 编写,大约 3000 行代码,使用了 SFS 异步 I/O 和 RPC 库 [^38] 的 Tame 扩展 [^31]。CRAQ 节点之间的所有网络功能都通过 Sun RPC 接口暴露。
5.1 集成 ZooKeeper(Integrating ZooKeeper)
如第 3.4 节所述,CRAQ 需要组成员服务的功能。我们使用 ZooKeeper 文件结构来维护每个数据中心内的节点列表成员关系。当客户端在 ZooKeeper 中创建一个文件时,它可以被标记为临时文件(ephemeral)。如果创建文件的客户端与 ZooKeeper 断开连接,临时文件会自动删除。在初始化期间,CRAQ 节点在 /nodes/dc_name/node_id 创建一个临时文件,其中 dc_name 是其数据中心的唯一名称(由管理员指定),node_id 是该节点在其节点所在数据中心内的唯一标识符。文件内容包含节点的 IP 地址和端口号。
CRAQ 节点可以查询 /nodes/dc_name 以确定其数据中心的成员列表,但无需定期检查列表变化,ZooKeeper 提供了进程在文件上创建监视(watch)的能力。CRAQ 节点在创建一个临时文件通知其他节点它已加入系统后,会在 /nodes/dc_name 的子节点列表上创建一个监视,从而保证它在节点添加或移除时收到通知。
当 CRAQ 节点收到创建新链的请求时,会在 /chains/chain_id 创建一个文件,其中 chain_id 是链的 160 位唯一标识符。链的放置策略(定义在第 3.1 节)决定了文件的内容,但它只包含此链的配置信息,而不是链当前节点的列表。任何参与链的节点都将查询链文件并在其上放置一个监视,以便在链元数据更改时得到通知。
尽管这种方法要求节点跟踪整个数据中心的 CRAQ 节点列表,但我们选择了这种方法,而不是另一种方法——即节点为其所属的每条链注册其成员关系(即链元数据显式命名链的当前成员)。我们假设链的数量通常至少比系统中的节点数量高一个数量级,或者链的动态性可能显著高于节点加入或离开系统(回想一下,CRAQ 是为托管数据中心设计的,而不是对等(peer-to-peer)设置)。在相反假设成立的部署中,可以采用在协调服务中显式跟踪每条链成员关系的替代方法。如有必要,当前方法的可扩展性也可以通过让每个节点仅跟踪数据中心节点的子集来提高:我们可以根据 node_id 前缀将节点列表分区到 /nodes/dc_name/ 内的单独目录中,节点只监视其自身及附近的前缀。
值得注意的是,我们能够通过构建 tame 风格的包装函数(wrapper functions)将 ZooKeeper 的异步 API 函数集成到我们的代码库中。这使我们能够在我们(对 ZooKeeper 的)包装函数上 twait,这大大降低了代码复杂性。
5.2 链节点功能(Chain Node Functionality)
我们的 chainnode 程序实现了 CRAQ 的大部分功能。由于链式复制和 CRAQ 的许多功能相似,该程序根据运行时配置设置,既可以作为链式复制节点运行,也可以作为 CRAQ 节点运行。
节点在加入系统时生成一个随机标识符,每个数据中心内的节点使用这些标识符将自己组织成一个单跳 DHT(分布式哈希表)[29, 45]。节点的链前驱和后继被定义为 DHT 环(ring)中的前驱和后继。链也由 160 位标识符命名。对于一条链 (C~i~),选择 (C~i~) 的 DHT 后继节点作为该链在该数据中心的第一个节点。接着,该节点的 (S) 个 DHT 后继节点完成该数据中心的子链,其中 (S) 在链元数据中指定。如果此数据中心是链的第一个(最后一个),那么此第一个(最后一个)节点就是链的最终头节点(尾节点)。
目前,节点之间或节点与客户端之间所有基于 RPC 的通信都是通过 TCP 连接进行的(Nagle 算法被关闭)。每个节点与其链的前驱、后继和尾节点维护一个连接的 TCP 连接池。请求在这些连接上被流水线化(pipelined)并以轮询(round-robin)方式发送。所有对象目前仅存储在内存中,尽管我们的存储抽象非常适合使用进程内键值存储(如 BerkeleyDB [^40]),我们正在集成它。
对于跨越多个数据中心的链,一个数据中心的最后一个节点与其后继数据中心的第一个节点保持连接。任何与数据中心外部节点保持连接的节点也必须在外部数据中心的节点列表上放置监视。不过请注意,当外部数据中心的节点列表发生变化时,订阅变化的节点只会从其本地 ZooKeeper 实例接收通知,从而避免了额外的跨数据中心流量。
5.3 处理成员关系变更(Handling Membership Changes)
对于正常的写入传播,CRAQ 节点遵循第 2.3 节的协议。然而,在恢复期间有时需要第二种类型的传播,称为反向传播(back-propagation):它有助于在节点添加和故障时保持一致性。例如,如果一个新节点作为现有链的头节点加入 CRAQ(根据其在 DHT 中的位置),链的先前头节点需要将其状态向后传播。但系统还需要在恢复期间对后续故障具有鲁棒性,这些故障可能导致反向传播的需求沿链向下级联(例如,如果现在的第二个链节点在完成向现在头节点的反向传播之前故障)。原始的链式复制论文没有考虑此类恢复问题,可能是因为它只描述了一个更中心控制和静态配置的链成员版本,其中新节点总是添加到链的尾部。
由于这些可能的故障情况,当新节点加入系统时,新节点从其前驱接收传播消息,并从其后继接收反向传播消息,以确保其正确性。新节点拒绝客户端对特定对象的读取请求,直到它与其后继达成一致。在这两种传播方法中,节点可以使用集合协调算法(set reconciliation algorithms)来确保在恢复期间只传播实际需要的对象。
反向传播消息总是包含节点关于对象的完整状态。这意味着不仅仅是发送最新版本,还要发送最新的干净版本以及所有未完成的(更新的)脏版本。这对于使刚加入系统的新节点能够响应未来的确认消息是必要的。正向传播支持两种方法。对于沿链向下传播的正常写入,只发送最新版本,但在从故障恢复或添加新节点时,会传输完整的状态对象。
现在让我们从节点 (N) 的角度考虑以下情况,其中 (L~C~) 是 (N) 负责的链 (C) 的长度。
节点添加(Node Additions):一个新节点 (A) 被添加到系统。
- 如果 (A) 是 (N) 的后继,(N) 将 (C) 中的所有对象传播给 (A)。如果 (A) 之前曾在系统中,(N) 可以先执行对象集协调以识别达到与链其余部分一致所需的指定对象版本。
- 如果 (A) 是 (N) 的前驱:
- 如果 (N) 不是头节点,(N) 将 (C) 中的所有对象反向传播给 (A)。
- 如果 (N) 是之前的尾节点,则 (A) 接管成为 (C) 的尾节点。
- 如果 (N) 的后继之前是尾节点,则 (N) 成为 (C) 的尾节点。
- 如果 (N) 之前是头节点,并且 (A) 的标识符在 DHT 中落在 (C) 和 (N) 的标识符之间,则 (A) 成为 (C) 的新头节点。
- 如果 (A) 在 (N) 的 (L~C~) 个前驱之内:
- 如果 (N) 是 (C) 的尾节点,它放弃尾节点职责并停止参与链。(N) 现在可以将其本地 (C) 对象的副本标记为可删除,但它只会惰性地回收此空间,以支持如果它稍后重新加入链 (C) 时更快的状态协调。
- 如果 (N) 的后继是 (C) 的尾节点,则 (N) 承担尾节点职责。
- 如果以上都不成立,则无需操作。
节点删除(Node Deletions):一个节点 (D) 被从系统中移除。
- 如果 (D) 是 (N) 的后继,(N) 将 (C) 中的所有对象传播给 (N) 的新后继(再次,最小化传输只到未知的、新鲜的对象版本)。即使该节点已经属于链,(N) 也必须传播其对象,因为 (D) 可能在传播未完成写入之前就故障了。
- 如果 (D) 是 (N) 的前驱:
- 如果 (N) 不是头节点,(N) 将所需对象反向传播给 (N) 的新前驱。(N) 需要反向传播其键,因为 (D) 可能在向其前驱发送未完成的确认之前,或者在其完成自身的反向传播之前故障。
- 如果 (D) 是 (C) 的头节点,则 (N) 承担头节点职责。
- 如果 (N) 是 (C) 的尾节点,它放弃尾节点职责,并将 (C) 中的所有对象传播给 (N) 的新后继。
- 如果 (D) 在 (N) 的 (L~C~) 个前驱之内,并且 (N) 是 (C) 的尾节点,(N) 放弃尾节点职责,并将 (C) 中的所有对象传播给 (N) 的新后继。
- 如果以上都不成立,则无需操作。
6 评估(Evaluation)
本节评估我们的链式复制(CR)和 CRAQ 实现的性能。在高层次上,我们有兴趣量化 CRAQ 按比例分配读取能力所带来的读取吞吐量收益。另一方面,脏对象的版本查询仍然需要分派到尾节点,因此我们也有兴趣评估工作负载混合变化时的渐近行为。我们还简要评估了 CRAQ 在广域网部署方面的优化。
所有评估均在 Emulab(一个受控网络测试平台)上进行。实验使用 pc3000 类型的机器运行,这些机器具有 3GHz 处理器和 2GB RAM。节点在 100Mbit 网络上连接。对于以下测试,除非另有说明,我们使用由三个节点组成的链存储单个对象,节点之间直接连接,没有添加合成延迟。此设置旨在更好地隔离单链的性能特征。除非注明,所有图表数据点均为中值(median);如有误差线,则对应第 99 百分位值(99th percentile values)。
为了确定两个系统中的最大只读吞吐量,我们首先在图 4 中改变客户端数量,该图显示了 CR 和 CRAQ 的总读取吞吐量。由于 CR 必须从单个节点读取,吞吐量保持恒定。CRAQ 能够从链中的所有三个节点读取,因此 CRAQ 吞吐量增加到 CR 的三倍。这些实验中的客户端维护着最大数量的未完成请求窗口(50),因此系统从未进入潜在的活锁(livelock)场景。
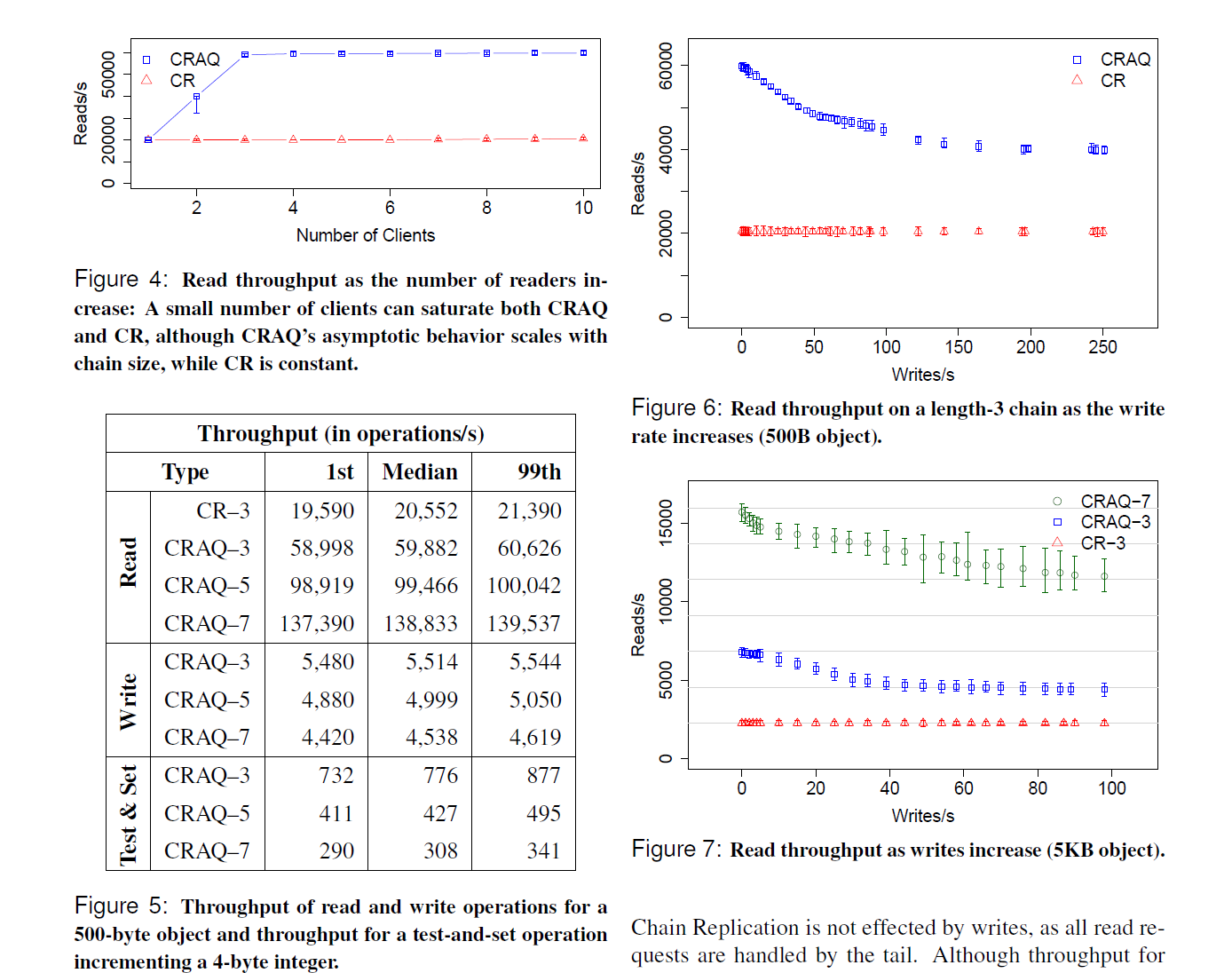
图 4:随着读取者数量增加,读取吞吐量:少量客户端即可使 CRAQ 和 CR 饱和,尽管 CRAQ 的渐近行为随链大小扩展,而 CR 是恒定的。
图 5:对 500 字节对象的读写操作吞吐量以及对一个 4 字节整数进行递增操作的测试并设置操作吞吐量。
图 6:在长度为 3 的链上,随着写入速率增加(500B 对象)的读取吞吐量。
图 7:随着写入增加(5KB 对象)的读取吞吐量。
图 5 显示了读取、写入和测试并设置操作的吞吐量。在这里,我们将 CRAQ 链从三节点变化到七节点,同时维持只读、只写和仅事务(test-and-set)的工作负载。我们看到读取吞吐量如预期般随链节点数量线性扩展。写入吞吐量随着链长度增加而下降,但幅度很小。一次只能有一个测试并设置操作未完成,因此吞吐量远低于写入。测试并设置操作的吞吐量也随着链长度的增加而下降,因为单个操作的延迟随链长度增加。
为了查看 CRAQ 在混合读/写工作负载下的表现,我们设置十个客户端持续从链中读取一个 500 字节的对象,同时一个客户端改变其对同一对象的写入速率。图 6 显示了作为写入速率函数的总读取吞吐量。请注意,链式复制不受写入的影响,因为所有读请求都由尾节点处理。尽管 CRAQ 的吞吐量开始时大约是 CR 的三倍(中值 59,882 次读/秒 对 20,552 次读/秒),但如预期,随着写入增加,该速率逐渐下降并趋于平稳,达到大约两倍的速率(39,873 次读/秒 对 20,430 次读/秒)。当写入使链饱和时,非尾节点总是脏的,要求它们总是首先向尾节点执行版本请求。然而,当这种情况发生时,CRAQ 仍然享有性能优势,因为尾节点对其组合的读取和版本请求的饱和点仍然高于仅处理读取请求时的饱和点。
图 7 重复了相同的实验,但使用 5 KB 对象而不是 500 字节对象。选择此值是因为它是常见大小(如小型 Web 图像),而 500 字节可能更适合较小的数据库条目(例如,博客评论、社交网络状态信息等)。同样,在只读设置下,CRAQ 在三节点链上的性能显著优于 CR(6,808 对 2,275 次读/秒),即使在高写入速率下也保持良好的表现(4,416 对 2,259 次读/秒)。此图还包括七节点链的 CRAQ 性能。在两种场景下,即使尾节点被请求饱和,它能够以远高于发送较大读取回复的速率回答小型版本查询,这使得总读取吞吐量仍然显著高于 CR。
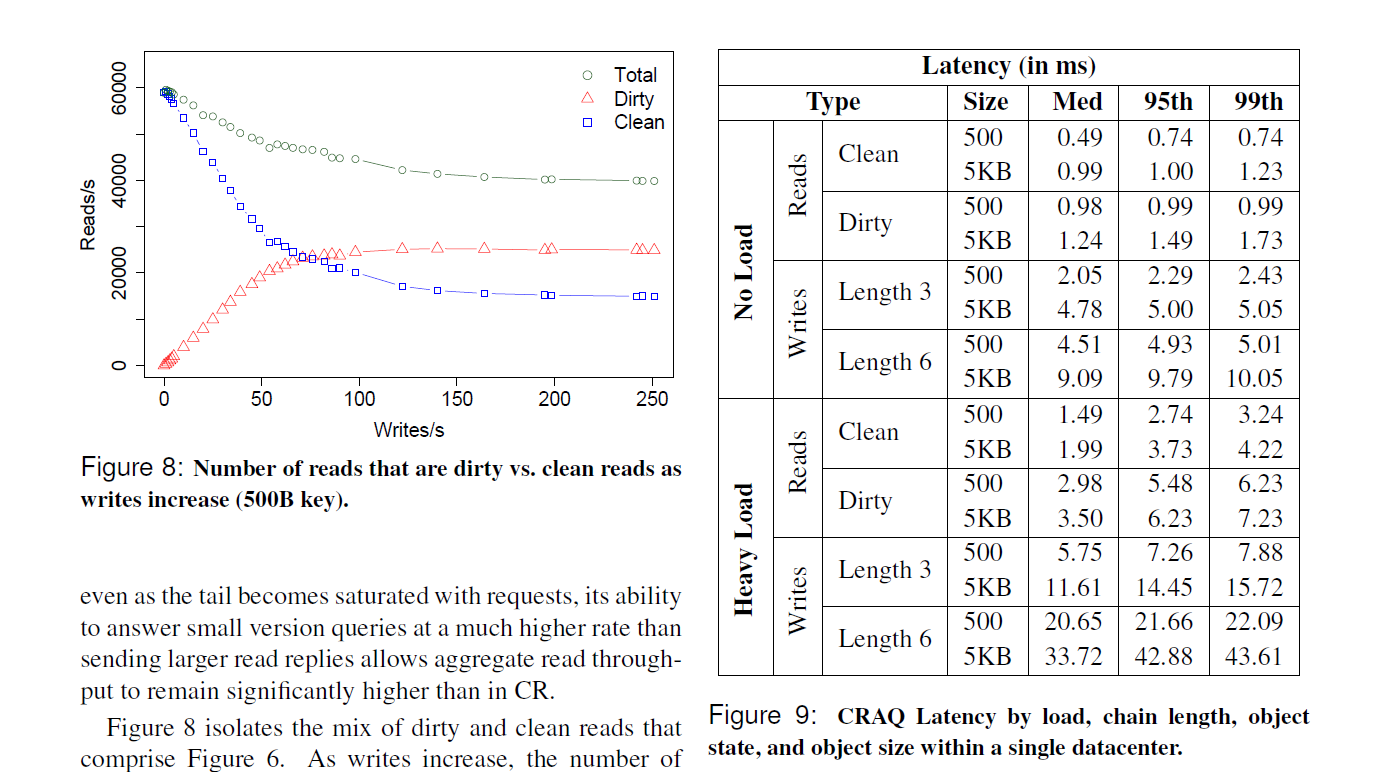
图 8:随着写入增加(500B 键),脏读与净读的数量。
图 9:在单个数据中心内,按负载、链长度、对象状态和对象大小划分的 CRAQ 延迟。
图 8 分离了构成图 6 的脏读和净读的混合情况。随着写入增加,净读请求的数量下降到其原始值的 25.4%,因为当写入使链饱和时只有尾节点是干净的。尾节点无法维持其自身的最大只读吞吐量(即总量的 33.3%),因为它现在还要处理来自其他链节点的版本查询。另一方面,如果总吞吐量保持恒定,脏读请求的数量将接近原始净读速率的三分之二,但由于脏读请求较慢,脏读请求的数量在 42.3% 处趋于平稳。这两个速率重构了观测到的总读取速率,在高写入争用期间,该速率收敛到只读吞吐量的 67.7%。
图 9 中的表格显示了在单个数据中心内,净读(clean reads)、脏读(dirty reads)、对三节点链的写入和对六节点链的写入的延迟(以毫秒计)。延迟显示了 500 字节和 5 KB 对象在操作是唯一未完成请求(无负载,No Load)以及当我们用许多请求使 CRAQ 节点饱和(高负载,High Load)时的延迟。正如预期,在重负载下延迟更高,延迟随键大小增加而增加。脏读总是比净读慢,因为产生了额外的往返时间(RTT),写延迟随链大小大致线性增加。
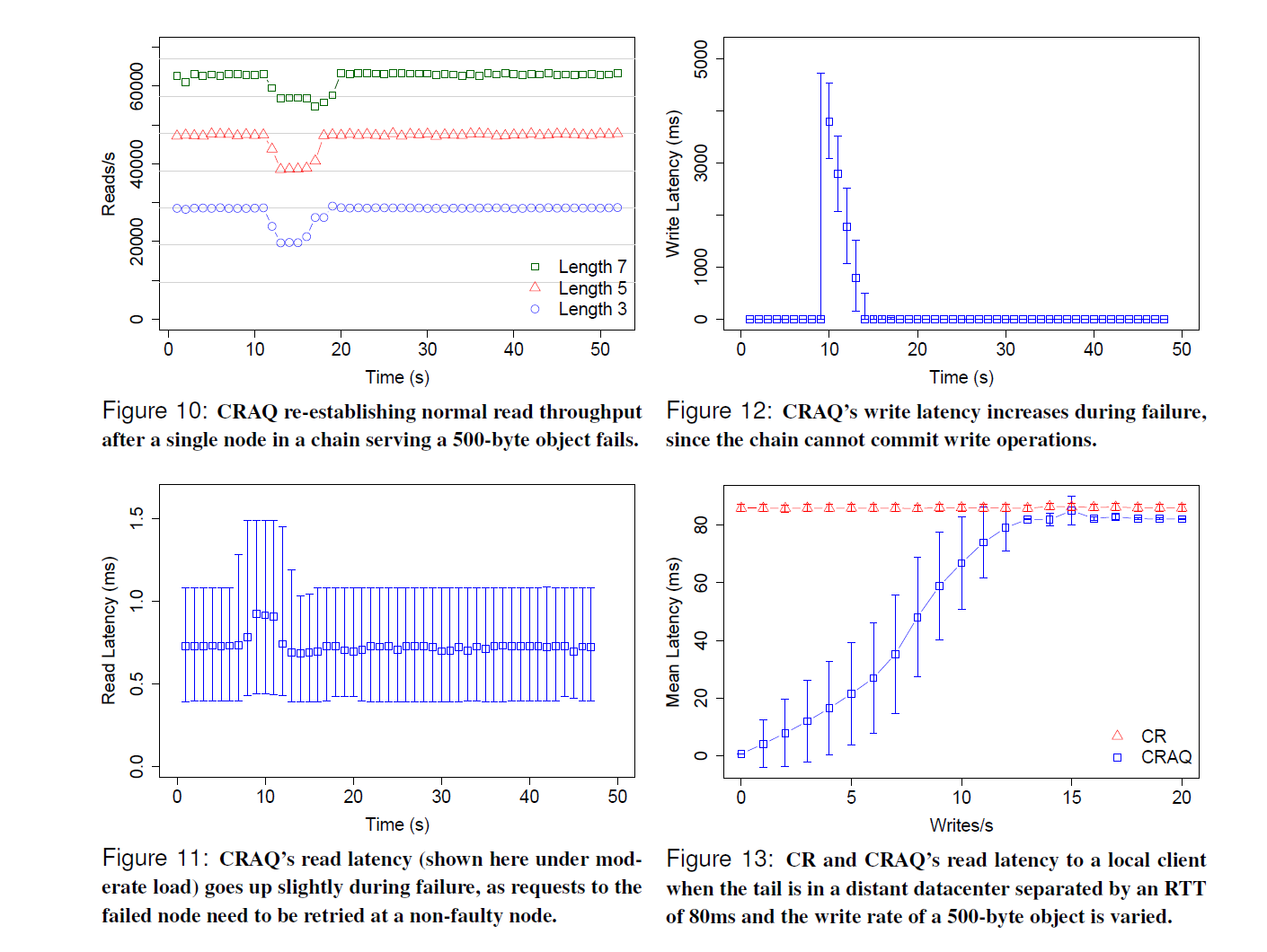
图 12:在故障期间,CRAQ 的写入延迟增加,因为链无法提交写入操作。
图 13:当尾节点位于相距 80ms RTT 的远程数据中心时,本地客户端对 CR 和 CRAQ 的读取延迟,以及一个 500 字节对象的写入速率变化情况。
图 11:在故障期间,CRAQ 的读取延迟(此处显示在中等负载下)略有上升,因为对故障节点的请求需要在非故障节点上重试。
图 10:在服务于 500 字节对象的链中单个节点故障后,CRAQ 重新建立正常的读取吞吐量。
图 10 展示了 CRAQ 从故障中恢复的能力。我们展示了长度为 3、5 和 7 的链随时间变化的只读吞吐量损失。在每个测试开始 15 秒后,链中的一个节点被终止。几秒钟后(节点超时并被 ZooKeeper 视为死亡所需的时间),一个新节点加入链,吞吐量恢复到其原始值。图上绘制的水平线对应于长度为 1 到 7 的链的最大吞吐量。这有助于说明故障期间的吞吐量损失大约等于 (1/C),其中 (C) 是链的长度。
为了测量故障对读写操作延迟的影响,图 11 和图 12 显示了长度为三的链在故障期间这些操作的延迟。尝试读取对象时收到错误的客户端会选择一个新的随机副本进行读取,因此故障对读取的影响较低。然而,在副本故障和由于超时将其从链中移除之间的时间段内,写入无法提交。这导致写延迟增加到完成故障检测所需的时间。我们注意到,这与任何其他需要所有活动副本参与提交的主/备复制策略的情况相同。此外,客户端可以选择配置写请求,使其在链头接受请求并向下传播到链后立即返回,而不是等待其提交。这降低了不需要强一致性的客户端的延迟。
最后,图 13 展示了 CRAQ 在跨数据中心的广域网部署中的效用。在此实验中,一条链构建在三个节点上,每个节点之间具有 80ms 的往返延迟(RTT)(大约是美国沿海地区之间的往返时间),这是使用 Emulab 的合成延迟控制的。读取客户端不位于链尾本地(否则可能导致像之前一样的局域网性能)。该图评估了随着工作负载混合变化的读取延迟;现在显示的是平均延迟(mean latency),标准差作为误差线(其他地方是中值和第 99 百分位)。由于尾节点不在本地,CR 的延迟始终很高,因为它总是产生广域网读取请求。另一方面,当没有写入发生时,CRAQ 几乎不产生延迟,因为读取请求可以在本地满足。然而,随着写入速率增加,CRAQ 读取越来越可能是脏的,因此平均延迟上升。一旦写入速率达到约 15 次写入/秒,在广域网链上传播写消息所涉及的延迟导致客户端的本地节点 100% 的时间处于脏状态,从而导致广域网版本查询。(CRAQ 的最大延迟比 CR 略低,因为只有元数据在广域网上传输,对于更大的对象,尤其是在慢启动(slow-start)场景下,这种差异只会增加。)尽管这种向 100% 脏状态的收敛发生在比以前低得多的写入速率下,但我们注意到,仔细的链放置允许尾节点数据中心内的任何客户端享受局域网性能。此外,非尾节点数据中心中满足一定最大不一致界限(maximum-bounded inconsistency)的客户端(见第 2.4 节)也可以避免广域网请求。
7 相关工作(Related Work)
分布式系统中的强一致性(Strong consistency in distributed systems)。
分布式服务器之间的强一致性可以通过主/备存储(primary/backup storage)[^3] 和两阶段提交协议(two-phase commit protocols)[^43] 提供。该领域的早期工作没有提供面对故障(例如,事务管理器故障)时的可用性,这导致了引入视图变更协议(view change protocols)(例如,通过领导者共识(leader consensus)[^33])来辅助恢复。随后该领域有大量工作;最近的例子包括链式复制和 Guerraoui 等人 [^25] 的基于环的协议(ring-based protocol),后者使用两阶段写入协议并在未提交写入期间延迟读取。与其到处复制内容,不如探索强一致性仲裁系统(quorum systems)[23, 28] 中读写集重叠之间的其他权衡。协议也扩展到恶意(Byzantine)设置,既用于状态机复制(state machine replication)[10, 34],也用于仲裁系统(quorum systems)[1, 37]。这些协议提供跨系统所有操作的线性化(linearizability)。本文不考虑拜占庭(Byzantine)故障——并且主要限制其对影响单个对象的操作的考虑——尽管将链式复制扩展到恶意设置是未来有趣的工作。
有许多提供强一致性保证的分布式文件系统例子,例如早期基于主/备的 Harp 文件系统 [^35]。最近,Boxwood [^36] 探索在提供严格一致性的同时导出各种更高层的数据抽象(如 B 树)。Sinfonia [^2] 提供轻量级的“迷你事务”来允许对存储节点中暴露的内存区域进行原子更新,这是一种优化的两阶段提交协议,非常适用于低写入争用的场景。CRAQ 对多链多对象更新使用乐观锁定(optimistic locking)深受 Sinfonia 的影响。
CRAQ 和链式复制 [^47] 都是基于对象的存储系统的例子,它们暴露整对象写入(更新)和扁平的对象命名空间。此接口类似于键值数据库 [^40] 提供的接口,将每个对象视为这些数据库中的一行。因此,CRAQ 和链式复制专注于对每个对象的操作顺序的强一致性,但通常不描述对不同对象的操作顺序。(我们在第 4.1 节中关于多对象更新的扩展是一个明显的例外。)因此,它们可以被视为因果一致性(causal consistency)走向极端的体现,其中只有对相同对象的操作是因果相关的。因果一致性在数据库的乐观并发控制(optimistic concurrency control)[^7] 和分布式系统的有序消息层(ordered messaging layers)[^8] 中都得到了研究。Yahoo! 的新数据托管服务 PNUTs [^12] 也提供每对象写入序列化(他们称之为每记录时间线一致性(per-record timeline consistency))。在单个数据中心内,他们通过具有完全有序传递(totally-ordered delivery)的消息服务实现一致性;为了跨数据中心提供一致性,所有更新都发送到本地记录主节点(local record master),然后主节点以提交顺序将更新传递给其他数据中心的副本。
我们使用的链自组织技术基于 DHT 社区开发的技术 [29, 45]。专注于对等(peer-to-peer)设置,CFS 在 DHT 之上提供只读文件系统 [^14];Carbonite 探索如何在瞬时故障下最小化副本维护的同时提高可靠性 [^11]。强一致性可变数据在 OceanStore [^32](在核心节点使用 BFT 复制)和 Etna [^39](使用 Paxos 将 DHT 划分为较小的副本组,并使用仲裁协议实现一致性)中得到了考虑。CRAQ 的广域网解决方案比这些系统更专注于数据中心,因此是拓扑感知的(topology-aware)。Coral [^20] 和 Canon [^21] 都考虑了分层 DHT 设计。
为可用性削弱一致性(Weakening Consistency for Availability)。
TACT [^49] 考虑了一致性和可用性之间的权衡,认为当系统约束不那么严格时可以支持较弱的一致性。eBay 使用了类似的方法:在拍卖远未结束前,消息传递和存储是最终一致的,但在拍卖结束前使用强一致性——即使以可用性为代价 [^46]。
许多文件系统和对象存储为了可扩展性或分区下的操作而牺牲了一致性。Google 文件系统(GFS)[^22] 是一个基于集群的对象存储,其设置与 CRAQ 类似。然而,GFS 牺牲了强一致性:GFS 中的并发写入不被序列化,读取操作也不与写入同步。设计具有较弱一致性语义的文件系统包括 Sprite [^6]、Coda [^30]、Ficus [^27] 和 Bayou [^42],后者使用流行病协议(epidemic protocols)执行数据协调。Amazon 的 Dynamo 对象服务 [^15] 使用了类似的八卦式反熵协议(gossip-style anti-entropy protocol),以支持“始终在线”的写入和在分区时继续操作。Facebook 的新 Cassandra 存储系统 [^16] 也只提供最终一致性。memcached [^18] 与关系型数据库的常见使用不提供任何一致性保证,而是依赖于正确的程序员实践;即使在多个数据中心之间维护松散的缓存一致性(cache coherence)也一直存在问题 [^44]。
CRAQ 的强一致性协议不支持在分区操作下的写入,尽管分区的链段可以回退到只读操作。这种在一致性、可用性和分区容忍性之间的权衡由 BASE [^19] 和 Brewer 的 CAP 猜想 [^9] 所考虑。
8 结论(Conclusions)
本文介绍了 CRAQ 的设计和实现,它是链式复制方法在强一致性方面的继承者。CRAQ 专注于扩展对象存储的读取吞吐量,特别是对于读密集型工作负载。它通过支持按比例分配查询(apportioned queries)来实现这一点:也就是说,将读取操作分配到链的所有节点上,而不是要求它们都由单个主节点处理。虽然看似简单,但 CRAQ 展示了具有显著可扩展性改进的性能结果:在写入争用很小的情况下与链长度成比例——即三节点链吞吐量提高 200%,七节点链提高 600%——并且,令人惊讶的是,即使在对象更新频繁时,仍然有值得注意的吞吐量改进。
除了改进链式复制的这种基本方法外,本文还关注了链式复制基础在各种更高级别应用中发挥作用的现实设置和要求。随着我们为多站点部署和多对象更新继续开发 CRAQ,我们正在努力将 CRAQ 集成到我们正在构建的其他几个需要可靠对象存储的系统中。这些包括支持动态服务迁移的 DNS 服务、对等辅助 CDN [^5] 的集合点服务器,以及一个大规模虚拟世界环境。探索这些应用在利用 CRAQ 的基本对象存储、广域网优化以及用于单键和多对象更新的更高级原语方面的设施,仍然是未来有趣的工作。
致谢(Acknowledgments)
作者感谢 Wyatt Lloyd、Muneeb Ali、Siddhartha Sen 以及我们的指导者(shepherd)Alec Wolman 对本文早期草稿的有益评论。我们也感谢犹他州的 Flux 研究小组提供对 Emulab 测试平台的访问。这项工作部分由 NSF NeTS-ANET Grant #0831374 资助。
参考文献(References)
[^1]: M. Abd-El-Malek, G. Ganger, G. Goodson, M. Reiter, and J. Wylie. Fault-scalable Byzantine fault-tolerant services. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2005.
[^2]: M. K. Aguilera, A. Merchant, M. Shah, A. Veitch, and C. Karamanolis. Sinfonia: a new paradigm for building scalable distributed systems. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2007.
[^3]: P. Alsberg and J. Day. A principle for resilient sharing of distributed resources. In Proc. Intl. Conference on Software Engineering, Oct. 1976.
[^4]: Amazon. S3 Service Level Agreement. http://aws.amazon.com/s3-sla/, 2009.
[^5]: C. Aperjis, M. J. Freedman, and R. Johari. Peer-assisted content distribution with prices. In Proc. SIGCOMM Conference on Emerging Networking Experiments and Technologies (CoNEXT), Dec. 2008.
[^6]: M. Baker and J. Ousterhout. Availability in the Sprite distributed file system. Operating Systems Review, 25(2), Apr. 1991.
[^7]: P. A. Bernstein and N. Goodman. Timestamp-based algorithms for concurrency control in distributed database systems. In Proc. Very Large Data Bases (VLDB), Oct. 1980.
[^8]: K. P. Birman. The process group approach to reliable distributed computing. Communications of the ACM, 36(12), 1993.
[^9]: E. Brewer. Towards robust distributed systems. Principles of Distributed Computing (PGDC) Keynote, July 2000.
[^10]: M. Castro and B. Liskov. Practical Byzantine fault tolerance. In Proc. Operating Systems Design and Implementation (OSDI), Feb. 1999.
[^11]: B.-G. Chun, F. Dabek, A. Haeberlen, E. Sit, H. Weatherspoon, F. Kaashoek, J. Kubiatowicz, and R. Morris. Efficient replica maintenance for distributed storage systems. In Proc. Networked Systems Design and Implementation (NSDI), May 2006.
[^12]: B. F. Cooper, R. Ramakrishnan, U. Srivastava, A. Silberstein, P. Bohannon, H.-A. Jacobsen, N. Puz, D. Weaver, and R. Yemeni. PNUTS: Yahoo!'s Hosted Data Serving Platform. In Proc. Very Large Data Bases (VLDB), Aug. 2008.
[^13]: CouchDB. http://couchdb.apache.org/, 2009.
[^14]: F. Dabek, M. F. Kaashoek, D. Karger, R. Morris, and I. Stoica. Wide-area cooperative storage with CFS. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2001.
[^15]: G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lak-shman, A. Pilchin, S. Sivasubramanian, P. Vosshall, and W. Vogels. Dynamo: Amazon's highly available key-value store. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2007.
[^16]: Facebook. Cassandra: A structured storage system on a P2P network. http://code.google.com/p/the-cassandra-project/, 2009.
[^17]: Facebook. Infrastructure team. Personal Comm., 2008.
[^18]: B. Fitzpatrick. Memcached: a distributed memory object caching system. http://www.danga.com/memcached/, 2009.
[^19]: A. Fox, S. D. Gribble, Y. Chawathe, E. A. Brewer, and P. Gauthier. Cluster-based scalable network services. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 1997.
[^20]: M. J. Freedman, E. Freudenthal, and D. Mazieres. Democratizing content publication with Coral. In Proc. Networked Systems Design and Implementation (NSDI), Mar. 2004.
[^21]: P. Ganesan, K. Gummadi, and H. Garcia-Molina. Canon in G Major: Designing DHTs with hierarchical structure. In Proc. Intl. Conference on Distributed Computing Systems (ICDCS), Mar. 2004.
[^22]: S. Ghemawat, H. Gobioff, and S.-T. Leung. The google file system. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2003.
[^23]: D. K. Gifford. Weighted voting for replicated data. In Proc. Symposium on Operating Systems Principles (SOSP), Dec. 1979.
[^24]: Google. Google Apps Service Level Agreement. http://www.google.com/apps/intl/en/terms/sla.html, 2009.
[^25]: R. Guerraoui, D. Kostic, R. R. Levy, and V. Quema. A high throughput atomic storage algorithm. In Proc. Intl. Conference on Distributed Computing Systems (ICDCS), June 2007.
[^26]: D. Hakala. Top 8 datacenter disasters of 2007. IT Management, Jan. 28 2008.
[^27]: J. Heidemann and G. Popek. File system development with stackable layers. ACM Trans. Computer Systems, 12(1), Feb. 1994.
[^28]: M. Herlihy. A quorum-consensus replication method for abstract data types. ACM Trans. Computer Systems, 4(1), Feb. 1986.
[^29]: D. Karger, E. Lehman, F. Leighton, M. Levine, D. Lewin, and R. Panigrahy. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web. In Proc. Symposium on the Theory of Computing (STOC), May 1997.
[^30]: J. Kistler and M. Satyanarayanan. Disconnected operation in the Coda file system. ACM Trans. Computer Systems, 10(3), Feb. 1992.
[^31]: M. Krohn, E. Kohler, and M. F. Kaashoek. Events can make sense. In Proc. USENIX Annual Technical Conference, June 2007.
[^32]: J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwinski, P. Eaton, D. Geels, R. Gummadi, S. Rhea, H. Weatherspoon, W. Weimer, C. Wells, and B. Zhao. OceanStore: An architecture for global-scale persistent storage. In Proc. Architectural Support for Programming Languages and Operating Systems (ASPLOS), Nov 2000.
[^33]: L. Lamport. The part-time parliament. ACM Trans. Computer Systems, 16(2), 1998.
[^34]: L. Lamport, R. Shostak, and M. Pease. The Byzantine generals problem. ACM Trans. Programming Language Systems, 4(3), 1982.
[^35]: B. Liskov, S. Ghemawat, R. Gruber, P. Johnson, L. Shrira, and M. Williams. Replication in the harp file system. In Proc. Symposium on Operating Systems Principles (SOSP), Aug. 1991.
[^36]: J. MacCormick, N. Murphy, M. Najork, C. A. Thekkath, and L. Zhou. Boxwood: Abstractions as the foundation for storage infrastructure. In Proc. Operating Systems Design and Implementation (OSDI), Dec. 2004.
[^37]: D. Malkhi and M. Reiter. Byzantine quorum systems. In Proc. Symposium on the Theory of Computing (STOC), May 1997.
[^38]: D. Mazieres, M. Kaminsky, M. F. Kaashoek, and E. Witchel. Separating key management from file system security. In Proc. Symposium on Operating Systems Principles (SOSP), Dec 1999.
[^39]: A. Multitacharoen, S. Gilbert, and R. Morris. Etna: a fault-tolerant algorithm for atomic mutable DHT data. Technical Report MIT-LCS-TR-993, MIT, June 2005.
[^40]: Oracle. BerkeleyDB v4.7, 2009.
[^41]: C. Patridge, T. Mendez, and W. Milliken. Host anycasting service. RFC 1546, Network Working Group, Nov. 1993.
[^42]: K. Petersen, M. Spreitzer, D. Terry, M. Theimer, , and A. Demers. Flexible update propagation for weakly consistent replication. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 1997.
[^43]: D. Skeen. A formal model of crash recovery in a distributed system. IEEE Trans. Software Engineering, 9(3), May 1983.
[^44]: J. Sobel. Scaling out. Engineering at Facebook blog, Aug. 20 2008.
[^45]: I. Stoica, R. Morris, D. Liben-Nowell, D. Karger, M. F. Kaashoek, F. Dabek, and H. Balakrishnan. Chord: A scalable peer-to-peer lookup protocol for Internet applications. IEEE/ACM Trans. Networking, 11, 2002.
[^46]: F. Travostino and R. Shoup. eBay's scalability odyssey: Growing and evolving a large ecommerce site. In Proc. Large-Scale Distributed Systems and Middleware (LADIS), Sept. 2008.
[^47]: R. van Renesse and F. B. Schneider. Chain replication for supporting high throughput and availability. In Proc. Operating Systems Design and Implementation (OSDI), Dec. 2004.
[^48]: Yahoo! Hadoop Team. Zookeeper. http://hadoop.apache.org/zookeeper/, 2009.
[^49]: H. Yu and A. Vahdat. The cost and limits of availability for replicated services. In Proc. Symposium on Operating Systems Principles (SOSP), Oct. 2001.