Amazon Aurora:面向高吞吐量云原生关系型数据库的设计考量
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, Xiaofeng Bao
Amazon Web Services
摘要
Amazon Aurora 是 Amazon Web Services (AWS) 提供的关系型数据库服务,专为 OLTP 工作负载设计。本文描述了 Aurora 的架构以及导致该架构的设计考量。我们认为,高吞吐量数据处理的核心约束已从计算和存储转移到网络。Aurora 为关系型数据库引入了一种新颖的架构来解决此约束,最显著的是将重做日志处理下推到专为 Aurora 构建的多租户横向扩展存储服务。我们阐述了这样做不仅减少了网络流量,还实现了快速崩溃恢复、无数据丢失的副本故障转移,以及容错、自愈的存储。然后,我们描述了 Aurora 如何使用高效的异步方案在众多存储节点上就持久化状态达成共识,从而避免了昂贵且通信密集的恢复协议。最后,在将 Aurora 作为生产服务运营超过 18 个月后,我们分享了从客户那里学到的关于现代云应用对其数据库层期望的经验教训。
关键词
数据库;分布式系统;日志处理;仲裁模型;复制;恢复;性能;OLTP
1. 引言
IT 工作负载正日益迁移到公共云提供商。这种全行业转型的重要原因包括能够按需灵活配置容量,并以运营支出(而非资本支出)模式支付费用。许多 IT 工作负载需要关系型 OLTP 数据库;提供与本地数据库相当或更优的能力对于支持这种长期转型至关重要。
在现代分布式云服务中,弹性和可扩展性越来越通过将计算与存储解耦 [10][24][36][38][39] 以及在多个节点间复制存储来实现。这样做使我们能够处理诸如替换故障或不可达主机、添加副本、从写入节点故障转移到副本、扩展或缩减数据库实例大小等操作。
传统数据库系统面临的 I/O 瓶颈在此环境中发生了变化。由于 I/O 可以分散在多租户集群中的多个节点和多个磁盘上,单个磁盘和节点不再成为热点。相反,瓶颈转移到请求 I/O 的数据库层和执行这些 I/O 的存储层之间的网络。除了每秒数据包数 (PPS) 和带宽的基本瓶颈之外,由于高性能数据库会并行地向存储集群发出写入,导致流量被放大。离群存储节点、磁盘或网络路径的性能可能主导响应时间。
尽管数据库中的大多数操作可以相互重叠,但存在几种需要同步操作的情况。这些情况会导致停顿和上下文切换。一种这样的情况是由于数据库缓冲区缓存未命中而导致的磁盘读取。读取线程在其读取完成之前无法继续。缓存未命中还可能产生额外的惩罚,即需要驱逐并刷新脏缓存页以容纳新页。后台处理(如检查点和脏页写入)可以减少这种惩罚的发生,但也会导致停顿、上下文切换和资源争用。
事务提交是另一个干扰源;一个事务提交的停顿会阻碍其他事务的进行。在云规模分布式系统中,使用诸如两阶段提交 (2PC) [3][4][5] 等多阶段同步协议处理提交具有挑战性。这些协议对故障容忍度低,而大规模分布式系统持续存在硬件和软件故障的“背景噪音”。它们也是高延迟的,因为大规模系统分布在多个数据中心。
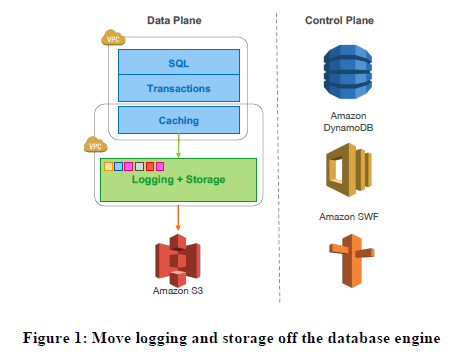
图 1:将日志和存储移出数据库引擎
本文中,我们描述了 Amazon Aurora,这是一种新的数据库服务,通过在高度分布式云环境中更积极地利用重做日志来解决上述问题。我们采用一种新颖的面向服务架构(见图 1),该架构包含一个多租户横向扩展存储服务,该服务抽象出一个虚拟化的分段重做日志,并与数据库实例集群松散耦合。尽管每个实例仍包含传统内核的大部分组件(查询处理器、事务、锁、缓冲区缓存、访问方法和撤消管理),但有几个功能(重做日志记录、持久存储、崩溃恢复和备份/恢复)被卸载到存储服务。
与传统方法相比,我们的架构具有三个显著优势。首先,通过将存储构建为一个跨多个数据中心的独立容错和自愈服务,我们保护数据库免受网络或存储层性能波动以及瞬时或永久故障的影响。我们观察到,持久性故障可以建模为长时间的可用性事件,而可用性事件可以建模为长时间的性能波动——设计良好的系统可以统一处理这些情况 [42]。其次,通过仅向存储写入重做日志记录,我们能够将网络 IOPS 减少一个数量级。一旦消除了这个瓶颈,我们就能积极优化许多其他争用点,相比我们起点的 MySQL 基础代码库获得了显著的吞吐量提升。第三,我们将一些最复杂和最关键的功能(备份和重做恢复)从数据库引擎中一次性昂贵的操作转变为在大规模分布式集群上分摊的连续异步操作。这带来了近乎即时的崩溃恢复(无需检查点)以及不影响前台处理的低成本备份。
本文中,我们描述了三个贡献:
- 如何理解云规模的持久性,以及如何设计能够应对相关故障的仲裁系统(第 2 节)。
- 如何通过将传统数据库的底层四分之一卸载到存储层来利用智能存储(第 3 节)。
- 如何在分布式存储中消除多阶段同步、崩溃恢复和检查点(第 4 节)。
然后,我们在第 5 节展示如何将这三种思想结合起来设计 Aurora 的整体架构,接着在第 6 节回顾性能结果,并在第 7 节分享我们学到的经验教训。最后,我们在第 8 节简要综述相关工作,并在第 9 节给出结论。
2 规模化持久性
如果数据库系统不做其他事情,它必须满足“写入的数据可被读取”的契约。并非所有系统都做到这一点。本节讨论我们仲裁模型背后的原理、为什么对存储进行分段,以及这两者如何结合不仅提供持久性、可用性和减少抖动,还帮助我们解决大规模管理存储集群的运维问题。
2.1 复制与相关故障
实例生命周期与存储生命周期相关性不高。实例会故障。客户会关闭它们。它们会根据负载进行扩缩容。因此,将存储层与计算层解耦是有益的。
一旦解耦,那些存储节点和磁盘也可能故障。因此,它们必须以某种形式复制以提供故障弹性。在大规模云环境中,节点、磁盘和网络路径故障存在持续的低水平背景噪音。每个故障可能持续时间和影响范围不同。例如,可能发生节点网络暂时不可用、重启期间临时停机,或者磁盘、节点、机架、叶或脊网络交换机甚至整个数据中心的永久故障。
容忍复制系统中故障的一种方法是使用基于仲裁的投票协议,如 [6] 所述。如果复制数据项的 V 个副本各被分配一票,则读或写操作必须分别获得 Vr 票的读仲裁或 V~w~ 票的写仲裁。为实现一致性,仲裁必须遵守两条规则。第一,每次读取必须感知到最近的写入,表述为 V~r~ + V~w~ > V。此规则确保用于读取的节点集与用于写入的节点集相交,且读仲裁至少包含一个具有最新版本的位置。第二,每次写入必须感知到最近的写入以避免写入冲突,表述为 V~w~ > V/2。
容忍单节点丢失的常见方法是将数据复制到 (V = 3) 个节点,并依赖 2/3 (V~w~ = 2) 的写仲裁和 2/3 (V~r~ = 2) 的读仲裁。
我们认为 2/3 仲裁不足。为理解原因,首先了解 AWS 中可用区 (AZ) 的概念。AZ 是区域的一个子集,通过低延迟链路连接到区域内的其他 AZ,但在大多数故障(包括电源、网络、软件部署、洪水等)方面是隔离的。跨 AZ 分发数据副本确保大规模下的典型故障模式只影响一个数据副本。这意味着可以简单地将三个副本中的每一个放在不同的 AZ,从而除了容忍较小的单个故障外,还能容忍大规模事件。
然而,在大型存储集群中,故障的背景噪音意味着在任何给定时刻,部分磁盘或节点可能已故障并正在修复。这些故障可能在 AZ A、B 和 C 的节点间独立分布。但是,由于火灾、屋顶损坏、洪水等原因导致的 AZ C 故障,将使那些同时在 AZ A 或 AZ B 发生故障的副本失去仲裁。此时,在 2/3 读仲裁模型下,我们将丢失两个副本,无法确定第三个副本是否是最新的。换句话说,虽然每个 AZ 中副本的单个故障是无关的,但一个 AZ 的故障是该 AZ 中所有磁盘和节点的相关故障。仲裁需要能够容忍一个 AZ 故障以及同时发生的背景噪音故障。
在 Aurora 中,我们选择了一个设计点:容忍 (a) 丢失整个 AZ 外加一个额外节点 (AZ+1) 而不丢失数据,(b) 丢失整个 AZ 而不影响写入数据的能力。我们通过跨 3 个 AZ 以 6 份复制每个数据项(每个 AZ 存放每个数据项的两个副本)来实现这一点。我们使用一个仲裁模型:6 票 (V = 6),写仲裁 4/6 (V~w~ = 4),读仲裁 3/6 (V~r~ = 3)。使用这种模型,我们可以 (a) 丢失一个 AZ 和一个额外节点(3 个节点故障)而不丧失读可用性,(b) 丢失任意两个节点(包括一个 AZ 故障)而保持写可用性。确保读仲裁使我们能够通过添加额外的副本副本来重建写仲裁。
2.2 分段存储
让我们考虑 AZ+1 是否提供足够的持久性。在此模型中提供足够的持久性,必须确保在修复其中一个故障所需的时间(平均修复时间 - MTTR)内,无关故障发生双重故障(平均故障间隔时间 - MTTF)的概率足够低。如果双重故障的概率足够高,我们可能在 AZ 故障时看到这种情况,导致仲裁失效。超过一定点后,降低无关故障的 MTTF 概率是困难的。我们转而专注于减少 MTTR 以缩小双重故障的脆弱时间窗口。为此,我们将数据库卷划分为小的固定大小段,当前大小为 10GB。每个段以 6 份复制到保护组 (PG) 中,因此每个 PG 由六个 10GB 段组成,分布在三个 AZ 中,每个 AZ 有两个段。存储卷是 PG 的串联集合,物理上使用大型存储节点集群实现,这些节点使用 Amazon Elastic Compute Cloud (EC2) 配置为带有附加 SSD 的虚拟主机。构成卷的 PG 随着卷的增长而分配。我们目前支持在未复制基础上可增长至 64 TB 的卷。
段现在是我们独立背景噪音故障和修复的单位。作为服务的一部分,我们监控并自动修复故障。一个 10GB 段在 10Gbps 网络链路上可在 10 秒内修复。我们需要在同一个 10 秒窗口内看到两个这样的故障,外加一个不包含这两个独立故障的 AZ 故障,才会导致仲裁丢失。根据我们观察到的故障率,即使对于我们为客户管理的数据库数量而言,这种情况也极不可能发生。
2.3 弹性带来的运维优势
一旦设计了一个天生能容忍长时间故障的系统,它自然也能容忍更短的故障。能处理 AZ 长期丢失的存储系统也能处理因电源事件或需要回滚的错误软件部署导致的短暂中断。能处理仲裁成员多秒可用性丢失的系统也能处理网络拥塞或存储节点负载的短暂时期。
由于我们的系统对故障有很高的容忍度,我们可以利用此特性执行导致段不可用的维护操作。例如,热管理很简单。我们可以将热磁盘或节点上的一个段标记为损坏,仲裁将通过迁移到集群中其他较冷节点来快速修复。操作系统和安全补丁对于正在打补丁的存储节点来说是短暂的不可用事件。甚至我们存储集群的软件升级也以这种方式管理。我们一次只升级一个 AZ,并确保一个 PG 中最多只有一个成员同时打补丁。这使我们能够在存储服务中使用敏捷方法和快速部署。
3. 日志即数据库
在本节中,我们解释为什么在第 2 节所述的分段复制存储系统上使用传统数据库会在网络 I/O 和同步停顿方面带来难以承受的性能负担。然后,我们解释我们的方法:将日志处理卸载到存储服务,并通过实验证明我们的方法如何能显著减少网络 I/O。最后,我们描述在存储服务中用于最小化同步停顿和不必要写入的各种技术。
3.1 放大写入的负担
我们对存储卷进行分段并将每个段以 6 份复制、使用 4/6 写仲裁的模型提供了高弹性。不幸的是,此模型对于像 MySQL 这样的传统数据库性能难以承受,因为它为每个应用写入生成许多不同的实际 I/O。高 I/O 量被复制放大,带来了沉重的每秒数据包 (PPS) 负担。此外,I/O 导致同步点,
使流水线停顿并延长延迟。虽然链式复制 [8] 及其替代方案可以减少网络成本,但它们仍然遭受同步停顿和累积延迟的影响。
让我们检查写入在传统数据库中如何工作。像 MySQL 这样的系统将数据页写入其暴露的对象(例如,堆文件、B 树等),并将重做日志记录写入预写日志 (WAL)。每个重做日志记录包含被修改页面的后映像和前映像之间的差异。可以将日志记录应用于页面的前映像以产生其后映像。
实践中,还必须写入其他数据。例如,考虑一个实现跨数据中心高可用性并在主备配置(如图 2 所示)中运行的同步镜像 MySQL 配置。AZ1 中有一个活跃 MySQL 实例,其网络存储位于 Amazon Elastic Block Store (EBS)。AZ2 中还有一个备用 MySQL 实例,其网络存储也位于 EBS。对主 EBS 卷的写入使用软件镜像与备用 EBS 卷同步。
图 2 显示了引擎需要写入的各种类型数据:重做日志、为支持时间点恢复而归档到 Amazon Simple Storage Service (S3) 的二进制(语句)日志、修改的数据页、为防止页面撕裂而对数据页进行的第二次临时写入(双写),最后是元数据 (FRM) 文件。该图还显示了实际 I/O 流的顺序如下:在步骤 1 和 2 中,写入被发送到 EBS,EBS 再将其发送到 AZ 本地镜像,当两者都完成时收到确认。接着,在步骤 3 中,使用同步块级软件镜像将写入暂存到备用实例。最后,在步骤 4 和 5 中,写入被写入备用 EBS 卷及其关联的镜像。
上述镜像 MySQL 模型之所以不理想,不仅因为其写入数据的方式,还因为其写入的数据内容。首先,步骤 1、3 和 5 是顺序且同步的。延迟是累加的,因为许多写入是顺序的。抖动被放大,因为即使在异步写入时,也必须等待最慢的操作,使系统受制于
1043
===== 第 4 页 =====
离群值。从分布式系统的角度来看,此模型可视为具有 4/4 写仲裁,易受故障和离群性能影响。其次,由 OLTP 应用程序产生的用户操作会导致多种不同类型的写入,通常以多种方式表示相同的信息——例如,为防止存储基础架构中的页面撕裂而写入双写缓冲区。
3.2 将重做处理卸载到存储 当传统数据库修改数据页时,它会生成一个重做日志记录并调用日志应用器(log applicator),该应用器将重做日志记录应用到内存中页面的前映像以生成其后映像。事务提交要求日志被写入,但数据页的写入可以延迟。
[\begin{array}{|c|c|c|} \hline \text{配置} & \text{事务数} & \text{每事务I/O数} \ \hline \text{镜像 MySQL} & 780,000 & 7.4 \ \hline \text{带副本的 Aurora} & 27,378,000 & 0.95 \ \hline \end{array}]
图 3:Amazon Aurora 中的网络 I/O
在 Aurora 中,跨越网络的唯一写入是重做日志记录。数据库层从不写入页面——不为后台写入,不为检查点,也不为缓存驱逐。相反,日志应用器被下推到存储层,在那里它可以用于在后台或按需生成数据库页面。当然,从头开始为每个页面重新生成其完整的修改链是极其昂贵的。因此,我们在后台持续物化数据库页面,以避免每次按需从头重新生成它们。请注意,从正确性的角度来看,后台物化完全是可选的:就引擎而言,日志就是数据库,存储系统物化的任何页面都只是日志应用的缓存。另请注意,与检查点不同,只有具有长修改链的页面才需要重新物化。检查点由整个重做日志链的长度控制。Aurora 页面物化则由特定页面的链长控制。
尽管为复制放大了写入,我们的方法仍显著降低了网络负载,并提供了性能和持久性。存储服务可以以极其并行的方式横向扩展 I/O,而不影响数据库引擎的写入吞吐量。例如,图 3 显示了一个 Aurora 集群,其中有一个主实例和多个副本实例部署在多个 AZ 上。在此模型中,主实例只将日志记录写入存储服务,并将这些日志记录以及元数据更新流式传输给副本实例。I/O 流根据共同目标(逻辑段,即 PG)对完全有序的日志记录进行批处理,并将每个批次传递给所有 6 个副本,在该批次持久化到磁盘后,数据库引擎等待 6 个副本中 4 个的确认,以满足写仲裁并将相关日志记录视为已持久化或硬化(hardened)。副本使用重做日志记录对其缓冲区缓存应用更改。
为测量网络 I/O,我们使用 SysBench [9] 纯写入工作负载对上述两种配置进行了测试:一种是跨多个 AZ 的同步镜像 MySQL 配置,另一种是跨多个 AZ 部署副本的 RDS Aurora。两种情况下,测试都针对运行在 r3.8xlarge EC2 实例上的数据库引擎运行 30 分钟。
表 1:Aurora 与 MySQL 的网络 I/O 对比
[\begin{array}{|c|c|c|} \hline \text{配置} & \text{事务数} & \text{每事务I/O数} \ \hline \text{镜像 MySQL} & 780,000 & 7.4 \ \hline \text{带副本的 Aurora} & 27,378,000 & 0.95 \ \hline \end{array}]
我们的实验结果总结在表 1 中。在 30 分钟内,Aurora 能够维持的事务量是镜像 MySQL 的 35 倍。尽管 Aurora 将写入放大了 6 倍(且未计入 EBS 内的链式复制或 MySQL 的跨 AZ 写入),但 Aurora 数据库节点上每事务的 I/O 数比镜像 MySQL 少了 7.7 倍。每个存储节点看到的写入未被放大(因为它只是六个副本之一),导致该层需要处理的 I/O 减少了 46 倍。通过向网络写入更少数据而获得的节省,使我们能够积极复制数据以实现持久性和可用性,并并行发出请求以最小化抖动的影响。
将处理移至存储服务还通过最小化崩溃恢复时间来提高可用性,并消除了由后台进程(如检查点、后台数据页写入和备份)引起的抖动。
让我们检查崩溃恢复。在传统数据库中,崩溃后系统必须从最近的检查点开始,并重放日志以确保所有持久化的重做记录都已被应用。在 Aurora 中,持久化重做记录的应用发生在存储层,持续、异步且分布在集群中。对数据页的任何读取请求,如果该页面不是最新的,可能需要应用一些重做记录。因此,崩溃恢复的过程分散在所有的正常前台处理中。数据库启动时无需任何操作。
3.3 存储服务设计要点 我们存储服务的核心设计原则是最小化前台写入请求的延迟。我们将大部分存储处理移到后台。鉴于存储层前台请求的峰值与平均值之间存在自然波动,我们有充足的时间在前台路径之外执行这些任务。我们还有机会用 CPU 换取磁盘。例如,当存储节点忙于处理前台写入请求时,除非磁盘接近容量,否则没有必要运行旧页面版本的垃圾回收 (GC)。在 Aurora 中,后台处理与前台处理呈负相关。这与传统数据库不同,传统数据库中页面的后台写入和检查点与系统的前台负载呈正相关。如果系统积压了任务,我们将限制前台活动以防止长队列堆积。由于段以高熵分布在我们系统的各个存储节点上,一个存储节点的限制很容易通过我们的 4/6 仲裁写入来处理,表现为一个慢节点。
1044
===== 第 5 页 =====
每个单独的事务。跟踪部分完成的事务并撤销它们的逻辑保留在数据库引擎中,就像它是在写入简单的磁盘一样。但是,在重启时,在允许数据库访问存储卷之前,存储服务会进行自己的恢复,其重点不在于用户级事务,而在于确保数据库看到存储的统一视图,尽管其分布式的本质。
存储服务确定它能保证所有先前日志记录可用性的最高 LSN(这称为 VCL 或卷完成 LSN)。在存储恢复期间,所有 LSN 大于 VCL 的日志记录必须被截断。然而,数据库可以通过标记日志记录并将其标识为 CPL 或一致性点 LSN(Consistency Point LSN)来进一步约束允许截断的子集。因此,我们将 VDL 或卷持久化 LSN(Volume Durable LSN)定义为小于或等于 VCL 的最高 CPL,并截断所有 LSN 大于 VDL 的日志记录。例如,即使我们拥有直到 LSN 1007 的完整数据,但数据库可能已声明只有 900、1000 和 1100 是 CPL,那么我们必须截断到 1000。我们完成到 1007,但只持久化到 1000。
因此,完成性(Completeness)和持久性(Durability)是不同的,CPL 可以被视为界定某种有限形式的存储系统事务,这些事务必须按顺序被接受。如果客户端不需要这种区分,它可以简单地将每个日志记录标记为 CPL。实践中,数据库和存储的交互如下:
- 每个数据库级事务被分解为多个有序且必须原子执行的小事务 (MTRs)。
- 每个小事务由多个连续的日志记录组成(数量根据需要而定)。
- 小事务中的最后一个日志记录是一个 CPL。
在恢复时,数据库与存储服务通信以确定每个 PG 的持久化点,并用此来建立 VDL,然后发出命令截断 VDL 之上的日志记录。
4.2 正常操作
我们现在描述数据库引擎的“正常操作”,并依次关注写入、读取、提交和副本。
4.2.1 写入
在 Aurora 中,数据库持续与存储服务交互并维护状态以建立仲裁、推进卷持久性(VDL)并将事务注册为已提交。例如,在正常/前向路径中,当数据库收到每批日志记录的写仲裁确认时,它就推进当前的 VDL。在任何给定时刻,数据库中可能有大量并发活动事务,每个事务都在生成自己的重做日志记录。数据库为每个日志记录分配唯一有序的 LSN,但受限于一个约束:分配的 LSN 值不能大于当前 VDL 与一个称为 LSN 分配限制 (LAL) 的常数(当前设置为 1000 万)之和。此限制确保数据库不会领先存储系统太远,并在存储或网络跟不上时引入背压(back-pressure)来限制传入的写入。
请注意,每个 PG 的每个段只看到卷中影响驻留在该段上页面的日志记录子集。每个日志记录包含一个反向链接(backlink),标识该 PG 的前一个日志记录。这些反向链接可用于跟踪到达每个段的日志记录的完成点,以建立段完成 LSN (SCL)
图 4:Aurora 存储节点的 I/O 流量
让我们更详细地检查存储节点上的各种活动。如图 4 所示,它涉及以下步骤:(1) 接收日志记录并添加到内存队列,(2) 将记录持久化到磁盘并确认,(3) 组织记录并识别日志中的间隙(因为某些批次可能丢失),(4) 与对等节点通信(gossip)以填补间隙,(5) 将日志记录合并成新的数据页,(6) 定期将日志和新页面暂存到 S3,(7) 定期垃圾回收旧版本,(8) 定期验证页面上的 CRC 码。
请注意,不仅上述每个步骤都是异步的,而且只有步骤 (1) 和 (2) 处于前台路径中,可能影响延迟。
4. 日志向前推进
在本节中,我们描述日志如何从数据库引擎生成,以使持久状态、运行时状态和副本状态始终保持一致。特别是,我们将描述如何在没有昂贵的 2PC 协议的情况下高效实现一致性。首先,我们展示如何避免在崩溃恢复时进行昂贵的重做处理。接着,我们解释正常操作以及如何维护运行时和副本状态。最后,我们提供恢复过程的细节。
4.1 解决方案概述:异步处理
由于我们将数据库建模为重做日志流(如第 3 节所述),我们可以利用日志作为一个有序变更序列向前推进这一事实。实践中,每个日志记录有一个关联的日志序列号 (LSN),这是由数据库生成的单调递增的值。
这使我们能够通过以异步方式处理问题来简化用于维护状态的共识协议,而不是使用像 2PC 那样通信密集且对故障容忍度低的协议。在高层次上,我们维护一致性和持久性点,并在收到未完成存储请求的确认时不断推进这些点。由于任何单个存储节点可能错过了一个或多个日志记录,它们会与 PG 中的其他成员通信(gossip),寻找间隙并填补空缺。数据库维护的运行时状态使我们能够使用单段读取而非仲裁读取(除了在恢复时状态丢失需要重建的情况)。
数据库可能有多个未完成的独立事务,这些事务可以以不同于启动的顺序完成(达到完成且持久的状态)。假设数据库崩溃或重启,是否回滚的决定是针对
===== 第 6 页 =====
(SCL),它标识低于该 LSN 的所有 PG 日志记录都已被接收的最大 LSN。存储节点在相互通信(gossip)时使用 SCL 来查找并交换它们缺失的日志记录。
4.2.2 提交
在 Aurora 中,事务提交是异步完成的。当客户端提交事务时,处理提交请求的线程通过将其“提交 LSN”记录到单独的等待提交事务列表中,将该事务搁置一旁,然后继续执行其他工作。相当于 WAL 协议的机制基于:当且仅当最新的 VDL 大于或等于事务的提交 LSN 时,才完成提交。随着 VDL 推进,数据库识别出符合条件、正在等待提交的事务,并使用专用线程向等待的客户端发送提交确认。工作线程不会因提交而暂停,它们只是拉取其他待处理请求并继续处理。
4.2.3 读取
在 Aurora 中,与大多数数据库一样,页面从缓冲区缓存提供,只有当相关页面不在缓存中时才会导致存储 I/O 请求。
如果缓冲区缓存已满,系统会找到一个牺牲页(victim page)从缓存中驱逐。在传统系统中,如果牺牲页是“脏页”,则在替换前会将其刷新到磁盘。这是为了确保后续获取该页面始终能得到最新数据。虽然 Aurora 数据库在驱逐时(或任何其他地方)不写出页面,但它强制执行类似的保证:缓冲区缓存中的页面必须始终是最新版本。该保证通过以下协议实现:只有当页面的“页面 LSN”(标识与该页面最新更改关联的日志记录)大于或等于 VDL 时,才将其从缓存中驱逐。该协议确保:(a) 页面中的所有更改已在日志中持久化,(b) 在缓存未命中时,请求截至当前 VDL 的页面版本足以获得其最新的持久化版本。
在正常情况下,数据库不需要使用读仲裁来建立共识。当从磁盘读取页面时,数据库建立一个 读点(read-point),代表发出请求时的 VDL。然后,数据库可以选择一个相对于该读点是完整(complete)的存储节点,知道它将因此接收到最新版本。存储节点返回的页面必须与数据库中小事务 (MTR) 的预期语义一致。由于数据库直接管理向存储节点馈送日志记录并跟踪进度(即每个段的 SCL),它通常知道哪个段能够满足读取(即 SCL 大于读点的段),因此可以直接向拥有足够数据的段发出读取请求。
鉴于数据库知晓所有未完成的读取,它可以在任何时候按 PG 计算最小读点 LSN(Minimum Read Point LSN)。如果有读取副本,写入者会与它们通信(gossip)以建立跨所有节点的按 PG 最小读点 LSN。该值称为保护组最小读点 LSN (PGMRPL),代表“低水位线”,低于此水位线的所有 PG 日志记录都是不必要的。换句话说,存储节点段保证不会有读点低于 PGMRPL 的读取页面请求。每个存储节点从数据库获知 PGMRPL,因此可以通过合并较旧的日志记录来推进磁盘上的物化页面,然后安全地对其进行垃圾回收。
实际的并发控制协议在数据库引擎中执行,其方式与页面和撤消段组织在本地存储中的传统 MySQL 完全相同。
4.2.4 副本
在 Aurora 中,一个写入者和最多 15 个读取副本都可以挂载同一个共享存储卷。因此,读取副本不会增加额外的存储消耗或磁盘写入操作成本。为最小化延迟(lag),由写入者生成并发送到存储节点的日志流也发送给所有读取副本。在读取副本中,数据库通过依次考虑每个日志记录来消费此日志流。如果日志记录指向读取副本缓冲区缓存中的页面,则使用日志应用器将指定的重做操作应用到缓存中的页面。否则,它直接丢弃该日志记录。请注意,从写入者的角度来看,副本是异步消费日志记录的,写入者确认用户提交独立于副本。副本在应用日志记录时遵循两条重要规则:(a) 只应用 LSN 小于或等于 VDL 的日志记录,(b) 属于单个小事务的日志记录在副本缓存中被原子应用,以确保副本看到所有数据库对象的一致视图。实践中,每个副本通常只落后写入者很短的时间间隔(20 毫秒或更少)。
4.3 恢复
大多数传统数据库使用基于 ARIES [7] 的恢复协议,该协议依赖于存在能代表所有已提交事务精确内容的预写日志 (WAL)。这些系统还定期对数据库进行检查点(checkpoint),通过将脏页刷新到磁盘并向日志写入检查点记录,以粗粒度方式建立持久点。重启时,任何给定页面可能缺少一些已提交数据或包含未提交数据。因此,在崩溃恢复期间,系统会处理自上次检查点以来的重做日志记录,使用日志应用器将每个日志记录应用到相关的数据库页。此过程将数据库页面恢复到故障点的一致状态,之后可以通过执行相关的撤消日志记录来回滚崩溃期间正在进行的事务。崩溃恢复可能是一个昂贵的操作。减少检查点间隔有帮助,但代价是干扰前台事务。在 Aurora 中不需要这种权衡。
传统数据库的一个巨大简化原则是,相同的重做日志应用器既用于前向处理路径,也用于恢复路径(在恢复时,它在数据库离线状态下同步且在前台运行)。我们在 Aurora 中也依赖相同的原则,不同之处在于重做日志应用器与数据库解耦,在存储节点上并行且始终在后台运行。一旦数据库启动,它会与存储服务协作执行卷恢复(volume recovery),因此,即使崩溃时每秒处理超过 100,000 条写入语句,Aurora 数据库也能非常快速地恢复(通常在 10 秒以内)。
数据库在崩溃后确实需要重建其运行时状态。此时,它会联系每个 PG 的读仲裁段,这足以保证发现任何可能已达到写仲裁的数据。一旦数据库为每个 PG 建立了读仲裁,它就可以通过生成一个截断范围(truncation range)来重新计算 VDL,该范围将废除新 VDL 之后的所有日志记录,直至并包括一个结束 LSN(数据库可以证明该 LSN 至少与可能存在的最高未完成日志记录一样高)。
===== 第 7 页 =====
数据库推断此上限是因为它分配 LSN,并限制了分配能超过 VDL 多远(前面描述的 1000 万限制)。截断范围使用纪元号(epoch numbers)进行版本控制,并持久写入存储服务,这样在恢复被中断和重启的情况下,就不会对截断的持久性产生混淆。
数据库仍然需要执行撤消恢复(undo recovery)来回滚崩溃时进行中的事务的操作。然而,撤消恢复可以在数据库在线后进行,此时系统已经从撤消段构建了这些进行中事务的列表。
5 整体架构
在本节中,我们描述 Aurora 的构建模块,如图 5 所示(鸟瞰图)。
数据库引擎是“社区版” MySQL/InnoDB 的一个分支(fork),主要区别在于 InnoDB 如何读写磁盘数据。在社区版 InnoDB 中,写操作导致缓冲页中的数据被修改,相关的重做日志记录按 LSN 顺序写入 WAL 的缓冲区。在事务提交时,WAL 协议仅要求事务的重做日志记录被持久写入磁盘。实际修改的缓冲页最终也通过双写技术写入磁盘以避免部分页写入。这些页写入在后台发生,或在从缓存驱逐时发生,或在执行检查点时发生。除了 I/O 子系统,InnoDB 还包括事务子系统、锁管理器、B+树实现以及相关的“小事务”(MTR) 概念。MTR 是仅在 InnoDB 内部使用的构造,用于建模必须原子执行的成组操作(例如,B+树页的分裂/合并)。
在 Aurora 的 InnoDB 变体中,代表每个 MTR 中必须原子执行更改的重做日志记录被组织成批次,这些批次根据每个日志记录所属的 PG 进行分片(sharded),然后写入存储服务。每个 MTR 的最终日志记录被标记为一致性点 (CPL)。Aurora 在写入者(writer)中支持与社区 MySQL 完全相同的事务隔离级别(标准 ANSI 级别和快照隔离或一致读)。Aurora 读取副本持续接收写入者中事务开始和提交的信息,并利用此信息为本地(当然是只读的)事务提供快照隔离。请注意,并发控制完全在数据库引擎中实现,不影响存储服务。存储服务呈现底层数据的统一视图,在逻辑上与将数据写入社区版 InnoDB 的本地存储所得到的结果相同。
Aurora 利用 Amazon Relational Database Service (RDS) 作为其控制平面(control plane)。RDS 在数据库实例上包含一个称为主机管理器 (HM) 的代理,用于监控集群健康状况,并确定是否需要故障转移,或者是否需要替换实例。每个数据库实例都是集群的一部分,该集群由一个写入者和零个或多个读取副本组成。集群的实例位于单个地理区域(例如,us-east-1, us-west-1 等),通常放置在不同的 AZ 中,并连接到同一区域的存储集群。出于安全考虑,我们隔离数据库、应用程序和存储之间的通信。实践中,每个数据库实例可以在三个 Amazon Virtual Private Cloud (VPC) 网络上通信:客户 VPC(客户应用程序通过此与引擎交互)、RDS VPC(数据库引擎和控制平面通过此相互交互)和存储 VPC(数据库通过此与存储服务交互)。
存储服务部署在 EC2 VM 集群上,这些 VM 在每个区域至少跨越 3 个 AZ 进行配置,共同负责配置多个客户存储卷、对这些卷进行读写数据,以及对这些卷进行备份和恢复数据。存储节点操作本地 SSD,并与数据库引擎实例、其他对等存储节点以及备份/恢复服务交互,这些服务持续将更改的数据备份到 S3 并根据需要从 S3 恢复数据。存储控制平面使用 Amazon DynamoDB 数据库服务持久存储集群和存储卷配置、卷元数据以及备份到 S3 的数据的详细描述。对于编排长时间运行的操作(例如,数据库卷恢复操作或存储节点故障后的修复(重新复制)操作),存储控制平面使用 Amazon Simple Workflow Service。保持高水平的可用性需要在最终用户受到影响之前,主动、自动化地早期检测真实和潜在问题。存储操作的所有关键方面都使用指标收集服务进行持续监控,如果关键性能或可用性指标表明存在问题,这些服务会发出警报。
6 性能结果
在本节中,我们将分享将 Aurora 作为生产服务运行的经验,该服务于 2015 年 7 月实现“全面可用 (Generally Available)”。我们首先总结运行行业标准基准测试的结果,然后展示来自客户的一些性能结果。
6.1 标准基准测试结果
这里我们展示不同实验的结果,这些实验使用 SysBench 和 TPC-C 变体等业界标准基准测试比较 Aurora 和 MySQL 的性能。我们在附加了具有 30K 预配置 IOPS 的 EBS 卷的实例上运行 MySQL。除非另有说明,这些都是 r3.8xlarge EC2 实例,具有 32 个 vCPU 和 244GB 内存。
图 5:Aurora 架构:鸟瞰图
===== 第 8 页 =====
并采用 Intel Xeon E5-2670 v2 (Ivy Bridge) 处理器。r3.8xlarge 上的缓冲区缓存设置为 170GB。
6.1.1 随实例大小扩展
在此实验中,我们报告 Aurora 的吞吐量可以随实例大小线性扩展,并且在最大实例大小下,吞吐量可达 MySQL 5.6 和 MySQL 5.7 的 5 倍。请注意,Aurora 当前基于 MySQL 5.6 代码库。我们在 r3 系列的 5 个 EC2 实例(large, xlarge, 2xlarge, 4xlarge, 8xlarge)上运行 SysBench 纯读和纯写基准测试,数据集为 1GB(250 张表)。每个实例大小的 vCPU 和内存正好是相邻更大实例的一半。
6.1.2 不同数据大小下的吞吐量
在此实验中,我们报告即使使用更大的数据集(包括工作集超出缓存的负载),Aurora 的吞吐量也显著超过 MySQL。表 2 显示,对于 SysBench 纯写入工作负载,在数据库大小为 100GB 时,Aurora 可比 MySQL 快 67 倍。即使对于数据库大小为 1TB 且工作集超出缓存的负载,Aurora 仍然比 MySQL 快 34 倍。
6.1.3 随用户连接数扩展
在此实验中,我们报告 Aurora 的吞吐量可以随客户端连接数扩展。表 3 显示了运行 SysBench OLTP 基准测试的结果(以写入/秒为单位),连接数从 50 增加到 500 再到 5000。Aurora 从 40,000 写入/秒扩展到 110,000 写入/秒,而 MySQL 的吞吐量在约 500 个连接时达到峰值,然后随着连接数增加到 5000 而急剧下降。
6.1.4 随副本数量扩展
在此实验中,我们报告即使在更密集的工作负载下,Aurora 读取副本的延迟(lag)也显著低于 MySQL 副本。表 4 显示,随着工作负载从 1,000 到 10,000 写入/秒变化,Aurora 的副本延迟从 2.62 毫秒增长到 5.38 毫秒。相比之下,MySQL 的副本延迟从不到 1 秒增长到 300 秒。在 10,000 写入/秒时,Aurora 的副本延迟比 MySQL 小几个数量级。副本延迟的衡量标准是已提交事务在副本中可见所需的时间。
6.1.5 热点行争用下的吞吐量
在此实验中,我们报告在存在热点行争用的负载(如基于 TPC-C 基准的负载)下,Aurora 相对于 MySQL 表现非常出色。我们在 r3.8xlarge 实例上对 Amazon Aurora 和 MySQL 5.6/5.7 运行 Percona TPC-C 变体 [37],其中 MySQL 使用具有 30K 预配置 IOPS 的 EBS 卷。表 5 显示,随着工作负载从 500 连接/10GB 数据大小变化到 5000 连接/100GB 数据大小,Aurora 可以维持的吞吐量是 MySQL 5.7 的 2.3 倍到 16.3 倍。
\begin{table} \begin{tabular}{|l|l|l|} \hline 写入数/秒 & Amazon Aurora & MySQL \ \hline 1,000 & 2.62 & (<1000) \ \hline 2,000 & 3.42 & 1000 \ \hline 5,000 & 3.94 & 60,000 \ \hline 10,000 & 5.38 & 300,000 \ \hline \end{tabular} \end{table} 表 4:SysBench 纯写入的副本延迟(毫秒)
\begin{table} \begin{tabular}{|l|l|l|} \hline 连接数 & Amazon Aurora & MySQL \ \hline 50 & 40,000 & 10,000 \ \hline 500 & 71,000 & 21,000 \ \hline 5,000 & 110,000 & 13,000 \ \hline \end{tabular} \end{table} 表 3:SysBench OLTP(写入/秒)
图 7:Aurora 在纯写入工作负载下线性扩展
图 6:Aurora 在纯读取工作负载下线性扩展
===== 第 9 页 =====
| 连接数/大小/仓库数 | Amazon Aurora | MySQL 5.6 | MySQL 5.7 |
|---|---|---|---|
| 500/10GB/100 | 73,955 | 6,093 | 25,289 |
| 5000/10GB/100 | 42,181 | 1,671 | 2,592 |
| 500/100GB/1000 | 70,663 | 3,231 | 11,868 |
| 5000/100GB/1000 | 30,221 | 5,575 | 13,005 |
| 表 5:Percona TPC-C 变体 (tpmC) |
6.2 真实客户工作负载结果
在本节中,我们分享一些将生产工作负载从 MySQL 迁移到 Aurora 的客户报告的结果。
6.2.1 使用 Aurora 的应用响应时间
一家互联网游戏公司将其生产服务从 MySQL 迁移到运行在 r3.4xlarge 实例上的 Aurora。迁移前其 Web 事务的平均响应时间为 15 毫秒。相比之下,迁移后平均响应时间为 5.5 毫秒,提升了 3 倍,如图 8 所示。
图 8:Web 应用响应时间
6.2.2 使用 Aurora 的语句延迟
一家帮助学校管理学生笔记本电脑的教育技术公司将其生产工作负载从 MySQL 迁移到 Aurora。迁移前后(在 14:00 时)选择(SELECT)和逐记录插入(INSERT)操作的中位数(P50)和 95 百分位数(P95)延迟如图 9 和图 10 所示。
图 9:SELECT 延迟(P50 vs P95) 迁移前,P95 延迟在 40ms 到 80ms 之间,远差于约 1ms 的 P50 延迟。应用程序正经历我们在本文前面描述的那种糟糕的离群性能。然而,迁移后,两种操作的 P95 延迟都显著改善,并接近 P50 延迟。
图 10:INSERT 逐记录延迟(P50 vs P95)
6.2.3 多副本下的副本延迟
MySQL 副本通常显著落后于其写入者,并且如 Pinterest 的 Weiner [40] 所报告,会“导致奇怪的错误”。对于前面描述的教育技术公司,副本延迟经常飙升到 12 分钟,影响了应用正确性,因此副本仅用作备用。相比之下,迁移到 Aurora 后,4 个副本的最大延迟从未超过 20 毫秒,如图 11 所示。Aurora 提供的改进副本延迟使该公司能够将很大一部分应用负载分流到副本,从而节省成本并提高可用性。
图 11:最大副本延迟(每小时平均)
7. 经验教训
我们现在已经看到客户运行的各种应用,从小型互联网公司一直到运营大量 Aurora 集群的高度复杂的组织。虽然他们的许多用例是标准的,但我们关注云环境中常见并引领我们走向新方向的场景和期望。
7.1 多租户与数据库整合
我们的许多客户运营软件即服务 (SaaS) 业务,无论是专营还是带有一些他们试图迁移到 SaaS 模式的残余本地客户。我们发现这些客户通常依赖一个他们不容易更改的应用程序。因此,他们通常通过使用模式/数据库作为租户单位,将不同的客户整合到一个实例上。这种模式降低了成本:当不太可能所有客户同时活跃时,他们避免了为每个客户支付专用实例的费用。例如,我们的一些 SaaS 客户报告拥有超过 50,000 个自己的客户。
1049
===== 第 10 页 =====
此模型与众所周知的 Salesforce.com [14] 等多租户应用明显不同,后者使用多租户数据模型,并将多个客户的数据打包到统一模式下的单一表中,租户在行级别标识。因此,我们看到许多客户拥有包含大量表的整合数据库。小型数据库的生产实例超过 150,000 张表相当常见。这给管理元数据的组件(如字典缓存)带来了压力。更重要的是,此类客户需要 (a) 维持高水平的吞吐量和许多并发用户连接,(b) 一种仅在数据被使用时才配置和付费的模型,因为很难预先预测需要多少存储空间,以及 (c) 减少抖动,以便单个租户的峰值对其他租户的影响最小。Aurora 支持这些属性,非常适合此类 SaaS 应用。
7.2 高并发自动扩展工作负载
互联网工作负载通常需要处理基于突发意外事件的流量峰值。我们的一位大客户曾在一个非常受欢迎的全国性电视节目中特别亮相,经历了一次远超其正常峰值吞吐量的流量激增,而数据库并未承压。为支持此类峰值,数据库必须能够处理许多并发连接。这种方法在 Aurora 中是可行的,因为底层存储系统扩展性非常好。我们有几位客户每秒运行超过 8000 个连接。
7.3 模式演进
现代 Web 应用框架(如 Ruby on Rails)深度集成了对象关系映射工具。因此,应用开发者很容易对其数据库进行许多模式更改,这使得 DBA 管理模式演进具有挑战性。在 Rails 应用中,这些被称为“数据库迁移”(DB Migrations),我们亲耳听到 DBA 不得不“每周处理几十次迁移”,或者制定对冲策略以确保未来的迁移顺利进行。MySQL 提供宽松的模式演进语义并使用全表复制实现大多数更改,这加剧了情况。由于频繁的 DDL 是务实的现实,我们实现了一个高效的在线 DDL 实现,它 (a) 在每页基础上对模式进行版本控制,并使用其模式历史按需解码单个页面,(b) 使用写时修改原语(modify-on-write)惰性地将单个页面升级到最新模式。
7.4 可用性与软件升级
我们的客户对云原生数据库有苛刻的期望,这可能与我们如何操作集群以及我们修补服务器的频率相冲突。由于我们的客户主要将 Aurora 用作支持生产应用的 OLTP 服务,任何中断都可能是痛苦的。因此,许多客户对我们更新数据库软件的容忍度非常低,即使这相当于大约每 6 周计划停机 30 秒。因此,我们最近发布了一个新的零停机补丁 (ZDP) 功能,允许我们在运行中的数据库连接不受影响的情况下为客户打补丁。
如图 12 所示,ZDP 的工作原理是寻找一个没有活动事务的瞬间,在那个瞬间将应用状态欺骗(spoofing)到本地临时存储,修补引擎,然后重新加载应用状态。在此过程中,用户会话保持活动状态,并未察觉引擎在底层已更改。
8. 相关工作
在本节中,我们讨论其他贡献以及它们与 Aurora 所采用方法的关系。
计算与存储解耦。 尽管传统系统通常构建为单体守护进程 [27],但近期有工作将数据库内核分解为不同组件。例如,Deuteronomy [10] 是一个这样的系统,它将提供并发控制和恢复的事务组件 (TC) 与在 LLAMA [34](一种无锁日志结构缓存和存储管理器)之上提供访问方法的数据组件 (DC) 分离开来。Sinfonia [39] 和 Hyder [38] 是在横向扩展服务上抽象事务访问方法的系统,数据库系统可以使用这些抽象来实现。Yesquel [36] 系统实现了一个多版本分布式平衡树,并将并发控制与查询处理器分离。Aurora 在比 Deuteronomy、Hyder、Sinfonia 和 Yesquel 更低的层次解耦存储。在 Aurora 中,查询处理、事务、并发、缓冲区缓存和访问方法与日志记录、存储和恢复解耦,后者被实现为横向扩展服务。
分布式系统。 在面临分区(partitions)时正确性与可用性之间的权衡早已为人所知,主要结论是在网络分区情况下不可能实现单副本可串行化(one-copy serializability)[15]。最近,Brewer 的 CAP 定理在 [16] 中得到证明,指出高可用系统在存在网络分区时无法提供“强”一致性保证。这些结果以及我们在云规模复杂和相关故障方面的经验,促使我们制定了即使在 AZ 故障导致分区时也要实现的一致性目标。
Bailis 等人 [12] 研究了提供高可用事务 (HATs) 的问题,这些事务既不会在分区期间不可用,也不会产生高网络延迟。他们表明可串行化(Serializability)、快照隔离(Snapshot Isolation)和可重复读(Repeatable Read)隔离级别不符合 HAT,而大多数其他隔离级别可以实现高可用性。Aurora 通过做出一个简化假设(即任何时候只有一个写入者从单个有序域分配 LSN 生成日志更新)来提供所有这些隔离级别。
Google 的 Spanner [24] 提供外部一致性(externally consistent)[25] 的读写,以及数据库范围内时间戳一致的全局一致读取。这些特性使 Spanner 能够支持一致的备份、一致的分布式查询处理 [26] 和原子模式更新,所有这些都在全球范围内实现,甚至在存在进行中事务的情况下。正如 Bailis [12] 所解释,Spanner 高度专用于 Google 的读密集型工作负载,并依赖两阶段提交和两阶段锁来处理读/写事务。
图 12:零停机打补丁
并发控制。 弱一致性 (PACELC [17]) 和弱隔离模型 [18][20] 在分布式数据库中广为人知,并催生了乐观复制技术 [19] 以及最终一致系统 [21][22][23]。集中式系统中的其他方法范围广泛,包括基于锁的经典悲观方案 [28]、乐观方案(如 Hekaton [29] 中的多版本并发控制)、分片方法(如 VoltDB [30])以及 HyPer [31][32] 和 Deuteronomy 中的时间戳排序。Aurora 的存储服务为数据库引擎提供了持久化本地磁盘的抽象,并允许引擎决定隔离和并发控制。
日志结构存储。 日志结构存储系统由 LFS [33] 于 1992 年引入。最近,Deuteronomy 及其在 LLAMA [34] 和 Bw-Tree [35] 中的相关工作,在存储引擎栈的多个层面使用日志结构技术,并且像 Aurora 一样,通过写入增量(deltas)而非整个页面来减少写入放大。Deuteronomy 和 Aurora 都实现了纯重做日志记录(pure redo logging),并跟踪最高的稳定 LSN 以确认提交。
恢复。 虽然传统数据库依赖基于 ARIES [5] 的恢复协议,但一些近期系统出于性能考虑选择了其他路径。例如,Hekaton 和 VoltDB 在崩溃后使用某种形式的更新日志重建其内存状态。像 Sinfonia [39] 这样的系统通过使用进程对(process pairs)和状态机复制(state machine replication)等技术避免恢复。Graefe [41] 描述了一种具有按页日志记录链的系统,支持按需逐页重做,这可以使恢复变快。与 Aurora 类似,Deuteronomy 不需要重做恢复。这是因为 Deuteronomy 延迟事务,使得只有已提交的更新才会发布到持久存储。因此,与 Aurora 不同,Deuteronomy 中可以限制事务的大小。
9. 结论
我们将 Aurora 设计为一种高吞吐量 OLTP 数据库,在云规模环境中既不牺牲可用性也不牺牲持久性。核心理念是摆脱传统数据库的单体架构,将存储与计算解耦。特别是,我们将数据库内核的底层四分之一移至一个独立的、可扩展的分布式服务,该服务管理日志记录和存储。由于所有 I/O 都通过网络写入,我们的根本约束现在变成了网络。因此,我们需要专注于减轻网络负担和提高吞吐量的技术。我们依赖能够处理大规模云环境中复杂和相关故障并避免离群性能惩罚的仲裁模型、减少总 I/O 负担的日志处理,以及消除通信密集且昂贵的多阶段同步协议、离线崩溃恢复和分布式存储中检查点的异步共识。我们的方法带来了一个复杂性降低、易于扩展的简化架构,并为未来的进步奠定了基础。
10. 致谢
我们感谢整个 Aurora 开发团队在项目上的努力,包括我们当前的成员以及杰出的校友(James Corey, Sam McKelvie, Yan Leshinsky, Lon Lundgren, Pradeep Madhavarapu, and Stefano Stefani)。我们特别感谢使用我们服务运行生产工作负载的客户,他们慷慨地与我们分享了他们的经验和期望。我们也感谢指导老师(shepherds)在塑造本文过程中提出的宝贵意见。
参考文献
[1] B. Calder, J. Wang, et al. Windows Azure storage: A highly available cloud storage service with strong consistency. In SOSP 2011.
[2] O. Khan, R. Burns, J. Plank, W. Pierce, and C. Huang. Rethinking erasure codes for cloud file systems: Minimizing I/O for recovery and degraded reads. In FAST 2012.
[3] P.A. Bernstein, V. Hadzilacos, and N. Goodman. Concurrency control and recovery in database systems, Chapter 7, Addison Wesley Publishing Company, ISBN 0-201-10715-5, 1997.
[4] C. Mohan, B. Lindsay, and R. Obermarek. Transaction management in the R* distributed database management system". ACM TODS, 11(4):378-396, 1986.
[5] C. Mohan and B. Lindsay. Efficient commit protocols for the tree of processes model of distributed transactions. ACM SIGOPS Operating Systems Review, 19(2):40-52, 1985.
[6] D.K. Gifford. Weighted voting for replicated data. In SOSP 1979.
[7] C. Mohan, D.L. Haderle, B. Lindsay, H. Pirahesh, and P. Schwarz. ARIES: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging. ACM TODS, 17 (1): 94-162, 1992.
[8] R. van Renesse and F. Schneider. Chain replication for supporting high throughput and availability. In OSDI 2004.
[9] A. Kopytov. Sysbench Manual. Available at http://imvsql.com/wp-content/uploads/2014/10/sysbench-manual.pdf
[10] J. Levandoski, D. Lomet, S. Sengupta, R. Stutsman, and R. Wang. High performance transactions in deuteronomy. In CIDR 2015.
[11] P. Bailis, A. Fekete, A. Ghodsi, J.M. Hellerstein, and I. Stoica. Scalable atomic visibility with RAMP Transactions. In SIGMOD 2014.
[12] P. Bailis, A. Davidson, A. Fekete, A. Ghodsi, J.M. Hellerstein, and I. Stoica. Highly available transactions: virtues and limitations. In VLDB 2014.
[13] R. Taft, E. Mansour, M. Serafini, J. Duggan, A.J. Elmore, A. Aboulnaga, A. Pavlo, and M. Stonebraker. E-Store: fine-grained elastic partitioning for distributed transaction processing systems. In VLDB 2015.
[14] R. Woollen. The internal design of salesforce.com's multi-tenant architecture. In SoCC 2010.
[15] S. Davidson, H. Garcia-Molina, and D. Skeen. Consistency in partitioned networks. ACM CSUR, 17(3):341-370, 1985.
[16] S. Gilbert and N. Lynch. Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services. SIGACT News, 33(2):51-59, 2002.
[17] D.J. Abadi. Consistency tradeoffs in modern distributed database system design: CAP is only part of the story. IEEE Computer, 45(2), 2012.
[18] A. Adya. Weak consistency: a generalized theory and optimistic implementations for distributed transactions. PhD Thesis, MIT, 1999.
[19] Y. Saito and M. Shapiro. Optimistic replication. ACM Comput. Surv., 37(1), Mar. 2005.
[20] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O'Neil, and P. O'Neil. A critique of ANSI SQL isolation levels. In SIGMOD 1995.
[21] P. Bailis and A. Ghodsi. Eventual consistency today: limitations, extensions, and beyond. ACM Queue, 11(3), March 2013.
[22] P. Bernstein and S. Das. Rethinking eventual consistency. In SIGMOD, 2013.
[23] B. Cooper et al. PNUTS: Yahoo!'s hosted data serving platform. In VLDB 2008.
[24] J. C. Corbett, J. Dean, et al. Spanner: Google's globally-distributed database. In OSDI 2012.
[25] David K. Gifford. Information Storage in a Decentralized Computer System. Tech. rep. CSL-81-8. PhD dissertation. Xerox PARC, July 1982.
[26] Jeffrey Dean and Sanjay Ghemawat. MapReduce: a flexible data processing tool". CACM 53 (1):72-77, 2010.
[27] J. M. Hellerstein, M. Stonebraker, and J. R. Hamilton. Architecture of a database system. Foundations and Trends in Databases. 1(2) pp. 141-259, 2007.
[28] J. Gray, R. A. Lorie, G. R. Putzolu, I. L. Traiger. Granularity of locks in a shared data base. In VLDB 1975.
[29] P-A Larson, et al. High-Performance Concurrency control mechanisms for main-memory databases. PVLDB, 5(4): 298-309, 2011.
[30] M. Stonebraker and A. Weisberg. The VoltDB main memory DBMS. IEEE Data Eng. Bull., 36(2): 21-27, 2013.
[31] V. Leis, A. Kemper, et al. Exploiting hardware transactional memory in main-memory databases. In ICDE 2014.
[32] H. Muhe, S. Wolf, A. Kemper, and T. Neumann: An evaluation of strict timestamp ordering concurrency control for main-memory database systems. In IMDM 2013.
[33] M. Rosenblum and J. Ousterhout. The design and implementation of a log-structured file system. ACM TOCS 10(1): 26-52, 1992.
[34] J. Levandoski, D. Lomet, S. Sengupta. LLAMA: A cache/storage subsystem for modern hardware. PVLDB 6(10): 877-888, 2013.
[35] J. Levandoski, D. Lomet, and S. Sengupta. The Bw-Tree: A B-tree for new hardware platforms. In ICDE 2013.
[36] M. Aguilera, J. Leners, and M. Walfish. Yesquel: scalable SQL storage for web applications. In SOSP 2015.
[37] Percona Lab. TPC-C Benchmark over MySQL. Available at https://github.com/Percona-Lab/tpcc-mysql
[38] P. Bernstein, C. Reid, and S. Das. Hyder - A transactional record manager for shared flash. In CIDR 2011.
[39] M. Aguilera, A. Merchant, M. Shah, A. Veitch, and C. Karamanolis. Sinfonia: A new paradigm for building scalable distributed systems. ACM Trans. Comput. Syst. 27(3): 2009.
[40] M. Weiner. Sharding Pinterest: How we scaled our MySQL fleet. Pinterest Engineering Blog. Available at: https://engineering.pinterest.com/blog/sharding-pinterest-how-we-scaled-our-mysql-fleet
[41] G. Graefe. Instant recovery for data center savings. ACM SIGMOD Record. 44(2):29-34, 2015.
[42] J. Dean and L. Barroso. The tail at scale. CACM 56(2):74-80, 2013.