虚存管理
本节我们来描述对于虚存的管理部分。
整个系统的虚存管理位于 kernel/vm目录下。
这里我们仅大致描述下其主要框架,并结合一个用户程序运行的小示例进行分析。
1. 虚存分布
我们先来看看虚存空间的分布情况吧,直接看用户虚存即可。如下图所示:
用户程序虚存分布:
参见
/include/conf.h
/boot/kernel.ld
/user/user.ld
0xFFFFFFFFF ┌─────────────────────────────────────────────────────────┐
│ USER_MAP_TOP (0xFFFFFFFFF) │
│ [动态内存映射区] │
│ 范围: 0xA00000000 ~ 0xFFFFFFFFF │ SEG6
│ (USER_MAP_BOTTOM ~ USER_MAP_TOP) │
│ 用途: mmap/heap/共享库等 │
0xA00000000 ├─────────────────────────────────────────────────────────┤
.
.
.
│ ├─ .eh_frame (异常处理帧) │
│ ├─ .bss (未初始化数据, RW-) │
│ ├─ .data (已初始化数据, RW-) │
│ ├─ .rodata (只读数据, R--) │
│ ├─ .text (代码段, R-X) │ SEG5
│ PROVIDE(uend = .) // 程序结束地址 │
│ USER_TEXT_BASE = 0x200000000 │
│ [用户代码与数据段] (链接脚本定义) │
│ │
0x200000000 ├─────────────────────────────────────────────────────────┤
0x1FFFFF000 ├─────────────────────────────────────────────────────────┤
│ [线程栈区] (向下增长) │
│ USER_STACK_TOP(tid) = │
│ 0x200000000 - 0x1000 - tid*(USER_STACK_SIZE+4K) - (8)│ SEG4
│ ├─ 每个线程栈大小: 8MB (USER_STACK_SIZE) │
│ ├─ 栈间隔离: 4K guard page │
│ (tid=0 的栈顶: 0x200000000 - 0x1000 - 8 ≈ 0x1FFFFF000) │
.
.
.
├─────────────────────────────────────────────────────────┤
│ │
│ (固定占用 1页 + 4页参数页) │
│ ├─ 环境变量字符串(暂未实现) │
│ ├─ 参数字符串 (如 "./a.out") │ SEG3
│ ├─ 参数指针表 (char* argv[]) │
│ USER_ARGS_PAGE = 0x150000000 │
│ [参数与环境变量区] │
0x150000000 ├─────────────────────────────────────────────────────────┤
.
.
.
├─────────────────────────────────────────────────────────┤
│ 用户入口、出口 start.s user_entry │
│ 1. jalr elf.entry │
│ 2. exit(0) │
│ 所有用户共享,为了简单,直接映射到内核,用户可访问 │
内核代码段中 ├─────────────────────────────────────────────────────────┤
├ 内核的text,radata,data ┤ SEG2
0x80000000 ├─────────────────────────────────────────────────────────┤
│ 用于内核模块映射 │ SEG1
0x70000000 ├─────────────────────────────────────────────────────────┤
; 好吧,其实不一定从 0x200,000,000开始代码都行,我们的内核做了一些小适配
; 核心是入口函数 user_entry 跳转到你的开始位置,
; 开始位置由 elf.entry给出,也就是user.ld的起始地址
; 我们只是为了方便一统。我们将参数与栈放在这里放好固定了。
; 其余的,如果按照我们的 user.ld 来的话,将代码起始地址放在
; 0x1FFFFF000 和 0xA00000000 之间都行(需要页对齐)
; 如果靠近 0xA00000000 的话,需要注意越界。
; 其它空间最好别乱搞,我也不知道后面内核会拿某一块空间干莫事上面就是我们对于一个用户程序而言的一个完整的虚存分布。
我们来从下往上逐一解释(SEG 1 ~ SEG6):
内核空间
SEG1
本区域位于 0x70_000_000 - 0x80_000_000 - 1,大小合计256M。
// kernel/module/module.c
#define MOD_BASE 0x70000000本区域是我们用来当做内核模块的映射。当一个内核模块被插入内核的时候,会把模块的所有段一次性载入(为了避免不必要的麻烦,我们不是很想在内核模块运行中发生缺页)。这一块空间可以插入多个内核模块,模块与模块挨着存放。每个模块空间包含连续的代码、数据等段。
注:本段起始地址 MOD_BASE 没有作为配置直接存在
conf.h,因为这个地址的选择需要满足一定的条件。比如:我们编译的时候根据编译选项汇编出 auipc + jalr 的函数跳转方式,但这个跳转只能跳转+-2G的地址。如果需要跳转到导出的内核函数,那么当前的位置与内核函数的位置差距有一定限制。尽管SV39只用了39位而不是64位,不过那也很大了,极有可能会随随便便超出而导致不可跳转。我们担心“认为随便配的一块空间就好”的想法,因此单独写在这个源文件。
SEG2
本区域从 0x80_000_000 - 0x150_000_000 -1,大小合计3.25G。
本区域用于放置编译后的内核代码,数据等空间,且连续存放。目前我们的内核自身大小至少远远达不到这个最大的3.25G,因此不必考虑被撑爆导致压着后面的东西。
值得注意的是,这一块空间有用户程序的入口和出口函数,是用户空间的特例,允许用户访问。这是我们为了简化操作,将所有用户程序的入出口共享一个内核页面,我们能确保这一段空间绝对小于一个页面。这样对于用户而言,共用一个出入口函数段。这样用户程序在建立的时候,由于内核空间也被映射到用户空间,而内核页表是大家共用的,节省了在每个用户程序增加这一块虚存的管理步骤。
最初我们没有加上这一块空间,导致了即使能直接跳转到用户的main函数入口,看似正常运行,但是退出main函数的时候必须要显式的用return,加上这一段之后,相当于允许用户不显式return也行(虽然不符合规定,但是为了避免编译器报错,不显式return的前提是 void main)。
当然这样做在实际中会带来一些问题,但是至少我们暂时不用考虑。
用户空间
SEG3
本区域从0x150_000_000- conf,具体空间由conf.h配置,相关的参数见:
// 用户参数页列表占用 1 页(最多 4096 / 8 = 512 个参数,显示包含最后一个 NULL)
// (暂时固定,要改的话需要该代码 parse_argv )
#define USER_ARGS_MAX_CNT 1
#define USER_ARGV_MAX_SIZE 4 // 用户参数页大小 4 个页
#define USER_ARGV_MAX_CNT (PGSIZE / sizeof(char *)) // 最大参数个数
#define USER_ARGS_PAGE 0x150000000这一段区域主要用于程序的环境变量与参数配置。目前我们仅仅实现用于了exec加上参数传递给新的启动程序。
SEG4
本区域从0x1FFFFF000 - 8为栈顶,可配置,往下生长。
#define USER_STACK_SIZE (8 * 1024 * 1024) // 8 MB 栈
#define USER_STACK_TOP(tid) (USER_TEXT_BASE - 0x1000 - (tid) * (USER_STACK_SIZE + 0x1000) - 0x8) // 用户程序栈顶我们的内核为多线程提供了基础,但是并没有实现(你可以认为是在画饼,哈哈)。我们采取的是比较传统的进程分配资源,线程作为执行单位,而不是Linux中直接对于共享资源的使用。每个线程有自己的tid(thread id),分别从0开始编号。启动线程,或者说main函数所在的线程执行流,tid为0,当新增线程的时候,会分配新的thread_info,并tid递增分配。根据tid的不同,向下选择不同的栈,计算公式为如上,这样每个线程就有自己独立的用户栈。
SEG5
本区域从0x200_000_000 开始,同样,这个值是可配置的。
#define USER_TEXT_BASE 0x200000000 // 用户程序段基地址这一段区域用于用户程序的代码,数据,且连续存放。
需要注意的就是:用户的代码,数据等段必须要按页(PGSIZE)对齐。这是我们后面的虚存管理的基础。
这个内核很小,也仅仅是自己搞来玩,导致内核代码缺少中相关的检测对齐函数,没有如果没对齐,那我也不知道会发生什么,也懒得故意去测试^_^。
SEG6
本段区域0xA00_000_000 - 0xFFF_FFF_FFF,空间挺大的,这里就不算了。
#define USER_MAP_TOP 0xFFFFFFFFF // 用户映射区顶
#define USER_MAP_BOTTOM 0xa00000000 // 用户映射区域底我们目前这一块空间只用于实现了 mmap函数把文件映射进入内存,并没有其他什么额外的操作。对于以后的用户堆空间啥的,动态链接库啥的(如果有的话),看到时候再用这一段空间。
2. 虚存管理框架
2.1 SV39
本 2.1 小节的图片和表格数据均来自于https://marz.utk.edu/my-courses/cosc130/lectures/virtual-memory/
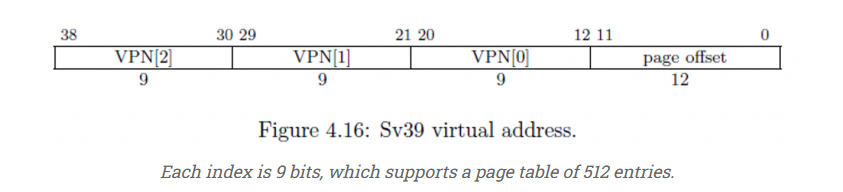
上图是SV39架构下的地址各字段结情况。但有趣的是,所支持的最大物理内存可以达到56位,远远超过虚存的39位。如下图所示:
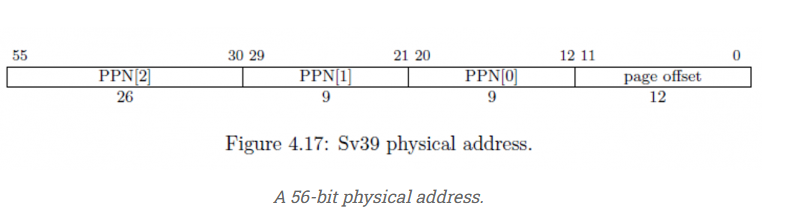
具体看页表项的话:

页表各项的表示的内容如下(好吧,这一表内容是直接CV大法过来的。。懒):
| 字段 | 功能 | 解释 |
|---|---|---|
| V | 有效 | 如果为 0,则整个条目无效。这将导致 MMU 抛出页面错误。 |
| R | 可读 | 如果这个位是 1,那么我们被允许从这个内存地址读取。否则,MMU 会导致加载时出现页面错误。 |
| W | 可写 | 如果这个 bit 是 1 ,那么我们被允许写入这个 memory 地址。否则,MMU 会导致 store 出现页面错误。 |
| X | 可执行 | 如果此位为 1,则允许 CPU 在此内存地址执行指令获取 (IF)。否则,MMU 会导致 IF 出现页面错误。 |
| U | 用户可访问 | 如果此位为 1,则允许用户应用程序在此内存位置进行 RWX(取决于上面的位)。如果此位为 0,则只有作系统可以在此内存位置进行 RWX。 |
| G | 全局 | 此内存地址用于多个应用程序,因此这是对缓存策略的提示。换句话说,当我们切换程序时,不要驱逐它。 |
| A | 访问 | 每当访问此内存地址(IF、load 或 store)时,由 CPU 自动设置。 |
| D | 脏 | 每当此内存地址写入 (stores) 时,由 CPU 自动设置。 |
| RSW | 软件保留 | 保留给 Software。操作系统可以在此处放置任何它想要的内容。 |
| Reserved | 保留 | 保留用于较大的条目(例如 SV48 和 SV56)。 |
2.2 Manage
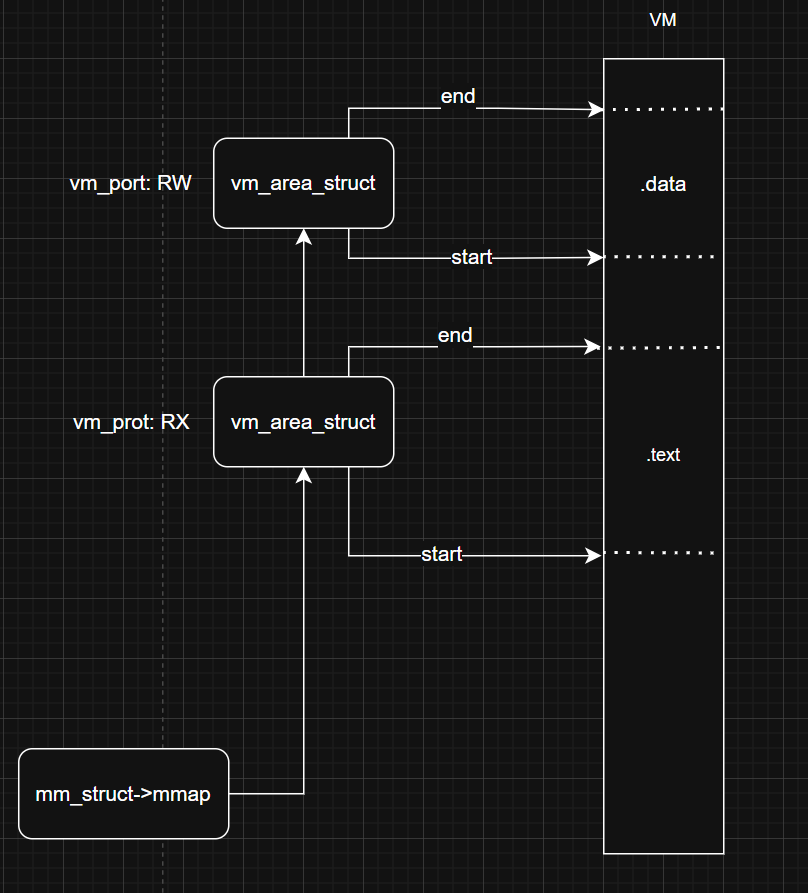
我们对每一个进程结构体设置了mm_struct结构体来管理整个进程内存资源。
struct mm_struct
{
pagetable_t pgd; // 指向顶级页表
struct vm_area_struct *mmap; // vma 链
...
};其中主要是页表指针和VMA链(我们目前有红黑树库,但是为了简化,仅采取简单的链表来链起来)。
对于每一段虚存的管理,采用vm_area_struct进行描述,具体结构如下:
// include/core/vm.h
// Virtual Memory Area
struct vm_area_struct
{
uint64_t vm_start; // 区域起始地址
uint64_t vm_end; // 区域结束地址
flags64_t vm_prot; // 区域标志 RWX
flags_t vm_flags; // 暂时没有使用
uint32_t vm_pgoff; // 文件页偏移
struct file *vm_file; // 关联文件
struct vm_area_struct *vm_next; // 下一个 vma
struct vm_operations_struct *vm_ops;// 该vma 上的操作方法
};其中vm_operations_struct如下:
struct vm_operations_struct
{
void (*fault)(struct thread_info *t, struct vm_area_struct *v,
uint64_t fault_addr); // 缺页中断
void (*close)(struct mm_struct *mm, struct vm_area_struct *v);
void (*dup)(struct mm_struct *mm, struct vm_area_struct *v, struct mm_struct *new_mm);
};3. 一个小栗子
我们这里仅仅口头分析一个小程序的运行,但是应该是经过检测的,吧?(因为我懒。。)
我们通过缺页异常(Page Fault)来分析整个虚存的管理。
大概的代码你可以认为是:
#include "user.h"
int var_a = 10;
int main()
{
var_a = 1;
exec("/bin/cat",NULL);
return 0;
}如果啊,程序编译后,让我们看一下它的程序头,我们只分析LOAD:
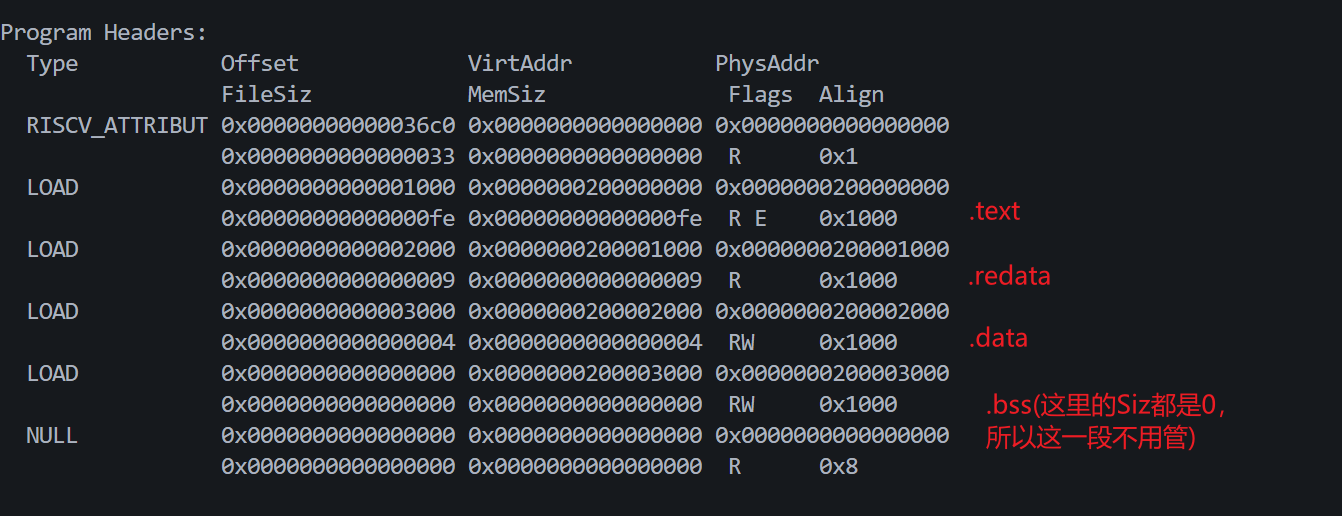
结合部分实际的反汇编代码而言:
0000000200000000 <main>:
200000000: 1141 addi sp,sp,-16
200000002: e406 sd ra,8(sp)
200000004: e022 sd s0,0(sp)
200000006: 0800 addi s0,sp,16
200000008: 00002797 auipc a5,0x2
20000000c: ff878793 addi a5,a5,-8 # 200002000 <var_a>
200000010: 4705 li a4,1
200000012: c398 sw a4,0(a5)
200000014: 4581 li a1,0
200000016: 00001517 auipc a0,0x1
20000001a: fea50513 addi a0,a0,-22 # 200001000 <debug+0xf0c>
20000001e: 04e000ef jal ra,20000006c <exec>
200000022: 0001 nop
200000024: 60a2 ld ra,8(sp)
200000026: 6402 ld s0,0(sp)
200000028: 0141 addi sp,sp,16
20000002a: 8082 ret0x200_000_000-0x200_000_000 - 1.text (不会超一个页面,这点小代码)0x200_001_000-0x200_000_100 - 1.rodata 放有"/bin/cat"字符串0x200_002_000-0x200_000_200 - 1.data 放有var_a
好了,剩下我们就开始运行了:
3.1 程序自身被exec加载
// kernel/trap/trap.c
//PS 这个函数确实写的太丑,不过我们很懒,能跑就行
__attribute__((noreturn)) int do_exec(const char *path, char *const argv[]) {
...
parse_elf_header()
}parse_elf_header会把我们上面说的所有的程序头加载进来填充组成vma链,对于该段在文件中的页偏移也会被记录在uint32_t vm_pgoff; struct file *vm_file;。这里,要求我们编译的时候必须满足按页对齐
对于不同的段,需要分配不同的vm_operations_struct类型。
注意:只加载了程序头,并没有加载任何执行程序的其他信息,包括执行代码和数据。
对于一个程序而言,我们只预先分配了一页栈。
此外,内核空间在用户虚存并没有
vm_area_struct描述。
3.2 来到梦开始的地方
经过中断返回到用户程序,再经过入口函数(kernel/start.S中user_entry)后,我们PC终于来到了这里 0x200_000_000,结果前方刚刚等着我们大展宏图的时候。。。。。结果咔一声。。
3.3 第一次缺页
这里经过检查,原来是没有页表被映射啊,MMU找不到0x200_000_000对应的实际物理地址。况且我们的代码段根本没有被加载进来。
下面是一个通用的处理流程:
使用当前地址在该进程的
vma链中查找(vm_start<fault_addr<vm_end),如果找不到,那么这一定是一个非法访问的地址(比如内核地址或者某个稀里古怪的地址),那么直接咔嚓把程序嗝屁儿。如果找得到是哪个
vma的,那么这确实是一个合法的地址空间。结合缺页异常时候报错的权限,现在我们就要检查权限,我们以报错写(Store/AMO)权限(也就是sscause中存放的报错原因显示)为例:- 如果
vma说:“老哥,我这里标注地清清楚楚,此地禁止写(Store/AMO)的啊”。那么也嗝屁儿吧。 - 如果
vma说:“老哥,俺挺你”,那么第一步检查权限就通过了
- 如果
执行缺页处理函数。
举个例子,假如是数据段因没有被加载内存而导致写错误。那么执行
vma->ops->fault函数去加载。那么数据段在哪里呢?还记得我们把文件的vm_pgoff和vm_file记录了下来吗?那么我们根据缺页地址,就可以算到在文件的哪个页面,然后读入、加载、映射一气呵成。比如。
inivm_start = 0x200_002_000 vm_file = xxx vm_pgoff = 1 // 表示该段在文件从头开始偏移的 1 * PGSIZE 处开始 fault_addr = 0x200_004_123 计算公式为:从vm_file->read page form PGDOWN(vm_pgoff * PGSIZE + fault_addr - vm_start) (我们以PGSIZE为0x1000,也就是4096为例) 1 * 0x1000 + 0x200_004_123 - 0x200_002_000 => 0x3_123 取页面向下对齐 => 0x3_000 也就是我们要通过 vm_file 把文件的 0x3_000 开始读一个页面加载进入内存 读入内存后,然后把这个页面给映射到缺页所在的虚拟地址页面,按照上面这个例子是 0x200_004_000不同段的缺页处理函数都不一样:
- STACK:分配一页新页
- BSS:分配一块新页(初始化全0)
- TEXT,DATA,RODATA,MMAP:从磁盘读文件对应页
读文件涉及到睡眠,也就涉及到进程主动下处理机,这里我们不展开细节。
然后程序处理完毕。被唤醒后回来,此时他会发现现在可以执行了。
3.4 继续执行,访问变量缺页
一路顺风的日子是少见的,这里根据代码,他会访问变量var_a,这里也会发生缺页,执行流程和上面类似。
3.5 在系统调用这里,又来缺页
这里的路更加艰难险阻。程序使用了一个系统调用,看似传了一个字符串进入。但是实际上,只是传了一个该字符串的指针。
而且更要命的是,这个指针指向的字符串的页面还没有被加入内存。
!!!!!!!!!!!
!!!!!!!!!!!
这里就带来了一个安全性问题,内核空间内对用户传来的指针直接解引用问题:
如果该指针不合法,或者是缺页,等一堆异常情况,如果处理不当,很容易导致内核崩溃。
在Linux中,在用户和内核传输数据可以使用
copy_from_user和copy_to_user,这两个函数会对这个指针进行一系列检查。但是在我们的小作坊中,采取了铤而走险的方式,直接撸起袖子在刀尖上自由的舞蹈。。。。
!!!!!!!!!!!
!!!!!!!!!!!
坦白说,这其实是一个非非非非非非常常常常常常严重的问题。比如用户随便传一个内核地址(内核自身的所有一定是在内存的),然后内核程序就傻乎乎的去做了。。对于没有映射的内存,我们允许在内核中发生缺页,但是小作坊就是无所谓,按照上述相同的流程可处理。
我们这个内核本身就自己做出来玩的。。。因此,哈哈。
3.6 结束,也是新生
到了这里,exec执行完毕,他的新生(/bin/cat)也会走上和他以前类似的道路。